概要
まずは、今回挑戦した内容についてざっと説明しする。
DQN(Deep Q Network)と方策勾配法(Policy Gradient)を使ってゲームを攻略してみようとした。
ゲーム内容について
OpenAI Gymのatariに含まれているテニスゲームを題材として扱うことにした。
大学の授業で強化学習のプログラムを実装することになったので、何かよいものはないかとOpenAiGymの公式サイトを眺めててたら、丁度目に留まったのがテニスゲームだった。
他のインベーダゲームやブロック崩しのようにやっている人がざっと検索したところ見当たらなかったので挑戦することに決めた。
– https://gym.openai.com/envs/Tennis-v0/
ゲーム画面は以下の通り。

CPUが青色で、プレイヤーがオレンジ色だ。
このゲーム画面が入力として使われる。
ゲームの内容としては
– ポイントの計算方式は普通のテニスと一緒
– 取り得る選択肢の数は18個ある
– 同じ操作を2~4フレーム分続ける
– 一定フレーム経過しても試合が終了していない場合(ずっとサーブを打たずにいたりしている場合)強制終了
– チェンジコートあり
という感じ。
ゲームから得られる値は
– observation : ゲーム画面
– reward: 報酬 (ポイント獲ったら+1,獲られたら-1,それ以外0)
– terminal: ゲームが終了したかどうか(先に6ゲーム先取したら勝利)
の3つになる。
実装概要
今回挑戦するにあたって使ったのはDQNと方策勾配法の2つである。
使われるモデル自体は変わらないのだが、パラメータの更新の仕方(というより出力結果のとらえ方)が異なる。
DQN
DQNは強化学習で有名なQ学習を深層学習でも適用できるよう拡張されたものだ。
詳しい解説はほかのサイトを見てほしいが、与えられた状態から次のアクション(行動)を行った場合の価値を計算するというもの。
コードそのものは以下のサイトを参考にさせてもらった(ほぼそのまんま)
– DQNをKerasとTensorFlowとOpenAI Gymで実装する
変更したのはニューラルネットワークの層の数やプーリング層の構造。
最終的には以下のような構造になった。
| 名称 | kernel_size | strides | channels | activation |
|---|---|---|---|---|
| Conv2D | (8,8) | (4,4) | 32 | relu |
| Conv2D | (4,4) | (2,2) | 64 | relu |
| Conv2D | (3,3) | (1,1) | 64 | relu |
| MaxPooling | (2,2) | (2,2) | – | – |
| Conv2D | (3,3) | (1,1) | 128 | relu |
| Conv2D | (3,3) | (1,1) | 128 | relu |
| Conv2D | (3,3) | (1,1) | 256 | relu |
| GlobalAveragePooling | – | – | – | – |
| Dense | – | – | 512 | relu |
| Dense | – | – | 18 | – |
方策勾配法
方策勾配法は1回1回の行動ごとに報酬(もしくは損失)が与えられ、それが複数行動にわたって減衰率を伴って伝播される。出力される値がそれぞれの状態でとる行動の確率だとみなしているため、実際に取った行動における算出した確率と報酬の値を元に報酬を与える。
学習の目的としてはこの算出された報酬を最大化するというもの。
報酬は減衰率γを0.99として
ポイント中のtステップ目の報酬R_tを以下のようにする。Nはポイントとるのにかかったステップ数でr_iはiステップ目で得られたポイント
R_t = \sum^{N}_{i=t} r_i \gamma^{i-t} \\
ここで報酬は
r_i = \begin{cases}
0 (reward = 0) \
200 ( reward = 1) \
-200 (reward= -1)\
-1000 (reward=0\ and\ episode\ end) \
\end{cases}
と設定している。
この報酬をゲームごとに正規化を行い、報酬の値が最大化するようにパラメータを更新させていく。
なかなかサーブをせずにエピソードが終了することがあったので、そのときの損失を一番大きくした。
また、使用したネットワークはDQNのものと同一である。
実装
簡単な概要を書いたところでコードを一気に張り付けていく。
様々な紆余曲折があった結果であまりきれいではないがとりあえず記録として張っていく。
ベンチマークのスコアとして使ったのは直近500ポイント分の平均スコア。
DQN
コード
まずは必要モジュールのインポート
import gym # OpenAIgymのインストール import numpy as np import random import numpy as np from collections import deque from skimage.color import rgb2gray from skimage.transform import resize import keras from keras.models import Sequential from keras.layers import Conv2D, GlobalAveragePooling2D, Dense, MaxPooling2D, Flatten import cv2 import tensorflow as tf import matplotlib.pyplot as plt %matplotlib inline
強化学習の環境を立ち上げる。
env = gym.make('Tennis-v0')
print(env.action_space) # 18pattern action can be taken
18通りのアクション(行動)がとれることが分かる。
次にゲーム画面をモノクロにして縮小する部分の実装。
FRAME_WIDTH =84 # 入力に使う画像の幅 FRAME_HEIGHT = 84 # 入力に使う画像の高さ def preprocess(observation, last_observation): processed_observation=np.maximum(observation, last_observation) processed_observation = np.uint8(resize(rgb2gray(processed_observation), (FRAME_WIDTH,FRAME_HEIGHT))*255) return np.reshape(processed_observation,(1,FRAME_WIDTH,FRAME_HEIGHT))
Agentクラスを定義する。
このクラス内でニューラルネットワークの構築と学習、学習パターンの蓄積も行う。
学習する際は最近のいくつかのフレーム分の画像を3万パターンほど蓄積しておき、そこからランダムにいくつかのパターンを選んで学習するというもの。
<br /><br />INITIAL_EPSILON = 1.0 # ε-greedy法のεの初期値
FINAL_EPSILON = 0.1
ESPLORATION_STEPS = 1000000 # ε-greedy法のεが減少していくフレーム数
# かなり長めにとってみる(元のソースコードでは100万)
# 20000万ステップで収束する
STATE_LENGTH = 16 # 状態を構成するフレーム数
FRAME_WIDTH = 84
FRAME_HEIGHT = 84
LEARNING_RATE = 0.0025 # RMSPropで使われる学習率(0.00025) Adamでは0.0025を使ってみる
MOMENTUM = 0.95 # RMSPropで使われるモメンタム
MIN_GRAD = 0.01 # RMSPropで使われる0で割るのを防ぐための値
ACTION_INTERVAL = 4 # フレームスキップ数
INITIAL_REPLAY_SIZE = 20000 # 学習前に事前に確保するReplay Memory数
NUM_REPLAY_MEMORY = 30000 # 学習に使うReplay Memory
NUM_SAVE_MODEL = 50000
BATCH_SIZE=512
GAMMA=0.99 # 割引率
TRAIN_INTERVAL = 4
TARGET_UPDATE_INTERVAL = 10000
class Agent():
def __init__(self, num_actions):
self.num_actions = num_actions # 行動数
self.epsilon = INITIAL_EPSILON # ε-greedy法のεの初期化
self.epsilon_step = (INITIAL_EPSILON-FINAL_EPSILON)/ESPLORATION_STEPS
# εの減少率
self.time_step = 0
self.repeated_action = 0
self.score = [] # ポイントごとのスコア
self.t = 0 # タイムステップ
# フレームスキップ間にリピートする行動を保持するための変数
# Replay Memoryの初期化
self.replay_memory = deque()
# Q Networkの構築
self.s, self.q_values, self.q_network = self.build_network()
q_network_weights = self.q_network.trainable_weights
# Target Networkの構築
self.st, self.target_q_values, target_network = self.build_network()
target_network_weights = target_network.trainable_weights
# 定期的にTarget Networkを更新するための処理の構築
self.update_target_network = [target_network_weights[i].assign(q_network_weights[i]) \
for i in range(len(target_network_weights))]
# 誤差関数や最適化のための処理の構築
self.a, self.y, self.loss, self.grad_update = self.build_training_op(q_network_weights)
# Sessionの構築
self.sess = tf.InteractiveSession()
# 変数の初期化(Q Networkの初期化)
self.sess.run(tf.global_variables_initializer())
# Target Networkの初期化
self.sess.run(self.update_target_network)
self.loss_list = [0]
def build_network(self):
model = Sequential()
model.add(Conv2D(32, kernel_size=(8,8),strides=(4,4),activation='relu',
input_shape =(STATE_LENGTH,FRAME_WIDTH,FRAME_HEIGHT),
data_format='channels_first'))
model.add(Conv2D(64, kernel_size=(4,4),strides=(2,2),activation='relu',
data_format='channels_first',padding='same'))
model.add(Conv2D(64,kernel_size=(3,3),strides=(1,1), activation='relu',
data_format='channels_first',padding='same'))
model.add(MaxPooling2D(data_format='channels_first',padding='same'))
model.add(Conv2D(128,kernel_size=(3,3),strides=(1,1),activation='relu',
data_format='channels_first',padding='same'))
model.add(Conv2D(128,kernel_size=(3,3),strides=(1,1),activation='relu',
data_format='channels_first',padding='same'))
model.add(Conv2D(256,kernel_size=(3,3),strides=(1,1),activation='relu',
data_format='channels_first',padding='same'))
model.add(GlobalAveragePooling2D(data_format='channels_first'))
# model.add(Flatten())
model.add(Dense(512,activation='relu'))
model.add(Dense(self.num_actions))
s = tf.placeholder(tf.float32, [None, STATE_LENGTH,FRAME_WIDTH,FRAME_HEIGHT])
q_values = model(s)
print(model.summary())
return s, q_values, model
def build_training_op(self, q_network_weights):
a = tf.placeholder(tf.int64, [None]) # 行動
y = tf.placeholder(tf.float32, [None]) # 教師信号
a_one_hot = tf.one_hot(a,self.num_actions,1.0,0.0)
# 行動をone hot vectorに変換する
q_value = tf.reduce_sum(tf.multiply(self.q_values, a_one_hot),reduction_indices=1)
# 行動のQ値の計算
# エラークリップ
error = tf.abs(y-q_value)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0) # 0~1.0の間にerrorの値を収める
linear_part = error-quadratic_part
loss = tf.reduce_mean(0.5*tf.square(quadratic_part) + linear_part)
# 誤差関数
#optimizer = tf.train.RMSPropOptimizer(LEARNING_RATE,momentum=MOMENTUM,
# epsilon=MIN_GRAD) # 最適化手法を定義
optimizer = tf.train.AdamOptimizer(LEARNING_RATE)
grad_update = optimizer.minimize(loss, var_list=q_network_weights)
#if self.t % NUM_SAVE_MODEL == 0:
# q_network_weights.save('./models/{}_dqn_1025.h5'.format(self.t))
return a, y, loss, grad_update
def get_initial_state(self,observation,last_observation):
processed_observation=np.maximum(observation,last_observation)
processed_observation=np.uint8(resize(rgb2gray(processed_observation),
(FRAME_WIDTH,FRAME_HEIGHT))*255)
state = [processed_observation for _ in range(STATE_LENGTH)]
return np.stack(state,axis=0)
def get_action(self, state):
action = self.repeated_action # 行動リピート
if self.t % ACTION_INTERVAL == 0:
if self.epsilon>=random.random() or self.t<INITIAL_REPLAY_SIZE:
action=random.randrange(self.num_actions)
else:
action=np.argmax(self.q_values.eval(
feed_dict={self.s: [np.float32(state/255.0)]}))
# Q値が最も高い行動を選択
self.repeated_action = action # フレームスキップ間にリピートする行動を格納
# εを線形に減少させる
if self.epsilon > FINAL_EPSILON and self.t>=INITIAL_REPLAY_SIZE:
self.epsilon -= self.epsilon_step
return action
def run(self, state, action, reward, terminal, observation):
# 次の状態を作成
next_state = np.append(state[1:,:,:],observation,axis=0)
reward = np.sign(reward)
if reward < 0:
reward = -3 # 失点の際の損失を大きくする
self.score.append(0)
elif reward == 0:
reward = -0.2 # サーブするのに躊躇する時間を短くするため
#1フレームごとにも損失を加える
else:
self.score.append(+1)
# Replay Memoryに遷移を保存
self.replay_memory.append((state,action,reward,next_state,terminal))
# Replay Memoryが一定数を超えたら、古い遷移から削除
if len(self.replay_memory)>NUM_REPLAY_MEMORY:
self.replay_memory.popleft()
if self.t > INITIAL_REPLAY_SIZE:
# Q Networkの学習
if self.t % TRAIN_INTERVAL == 0:
loss = self.train_network()
if self.t % 400 == 0 :
self.loss_list.append(loss)
# Target Network の更新
if self.t % TARGET_UPDATE_INTERVAL == 0:
self.sess.run(self.update_target_network)
if self.t % 50000 == 0:
self.q_network.save_weights('./models/q_network_weights_{}.h5'.format(self.t))
self.t += 1 # タイムステップ
return next_state
def train_network(self):
state_batch = []
action_batch = []
reward_batch = []
next_state_batch = []
terminal_batch = []
y_batch = []
# Replay Memoryからランダムにミニバッチをサンプル
minibatch = random.sample(self.replay_memory, BATCH_SIZE)
for data in minibatch:
state_batch.append(data[0])
action_batch.append(data[1])
reward_batch.append(data[2])
next_state_batch.append(data[3])
terminal_batch.append(data[4])
# 終了判定をTrueは1に、Falseは0に変換
terminal_batch = np.array(terminal_batch) + 0
target_q_values_batch = self.target_q_values.eval(
feed_dict={self.st:np.float32(np.array(next_state_batch)/255.0)})
# Target Networkで次の状態でのQ値を計算
y_batch = reward_batch + (1-terminal_batch)*GAMMA\
*np.max(target_q_values_batch,axis=1) # 教師信号を計算
loss,_ = self.sess.run([self.loss,self.grad_update], feed_dict={
self.s: np.float32(np.array(state_batch)/255.0),
self.a: action_batch,
self.y: y_batch
})
return loss
ここで骨子の部分は完成。残りは実行部分のみ。
NUM_EPISODES = 12000
NO_OP_STEPS = 30 # 何も操作しないステップ数
env = gym.make('Tennis-v0')
agent = Agent(num_actions = env.action_space.n)
reward_list_episode = []
reward_list = []
for _ in range(NUM_EPISODES):
flag = True
terminal = False
observation = env.reset() # ゲームの初期化
for __ in range(np.random.randint(1, NO_OP_STEPS)):
last_observation = observation
observation, ___, ___, ___ = env.step(0)
# 何もしない行動をとってつぎの画面を返す
state = agent.get_initial_state(observation, last_observation)
while not terminal:
last_observation = observation
action = agent.get_action(state)
observation, reward, terminal, ___ = env.step(action)
# 行動を実行して次の画面、報酬、終了判定を返す
env.render()
processed_observation = preprocess(observation, last_observation)
# 画面の前処理
state = agent.run(state, action, reward, terminal, processed_observation)
# train and take next action
if len(agent.score)%500 == 0 and len(agent.score) > 1 and flag:
if len(agent.score)==1000:
print("This score is the score of 1000 points")
print("The benchmark score is ", np.mean(agent.score[-500:]))
flag = False
if _ % 40 == 0 or _ == 10 or _ == 1 or _ == 20 or _==30:
print(agent.t,"steps has done")
plt.figure()
plt.subplot(1,2,1)
plt.title("{} episodes end".format(_))
plt.plot(np.convolve(agent.loss_list, np.ones(100)/100.0,mode='full'))
plt.subplot(1,2,2)
plt.title("score")
plt.plot(np.convolve(agent.score,np.ones(40)/40.0,mode='full'))
plt.show()
#if len(agent.score) >= 1000:
# break # 1000ポイント分データを取ったらいったんbreakする。
結果
<img src=”https://leck-tech.com/wp-content/uploads/2018/11/dqn_result.png” alt=”” width=”566″ height=”396″ class=”aligncenter size-full wp-image-552″ />
平均スコアは0.03を上回ることがほとんどなかった。
まだこの段階だとランダム性の行動をとっている段階ではあったのでそれが功を奏してたまたまポイントをとれていた可能性が高い。
少しはラリーを続けている感じが出てはいたがポイントにつながる気配は全くなかった。
てかコンピュータ強いな・・・
方策勾配法
次は方策勾配法。
こちらはDQNのコードを参考にして自分で組み立てた。(少しだけここのコードを参考にはした)
コード
まずは必要モジュールのインポート。
import gym # OpenAIgymのインストール import numpy as np import random import numpy as np from collections import deque from skimage.color import rgb2gray from skimage.transform import resize import keras from keras.models import Sequential from keras.layers import Conv2D, GlobalAveragePooling2D, Dense, MaxPooling2D, Flatten from keras.layers import Input, Dense from keras import optimizers from keras import utils import cv2 import tensorflow as tf import matplotlib.pyplot as plt %matplotlib inline
前処理の設定
env = gym.make('Tennis-v0')
NUM_ACTIONS = env.action_space.n # 取りうる選択肢の数
STATE_LENGTH = 8 # 何フレーム分のデータを使って一度に学習させるか
FRAME_WIDTH = 100
FRAME_HEIGHT = 100 # 少し大きめに画像をとる
def preprocess(observation, last_observation):
processed_observation=np.maximum(observation, last_observation)
processed_observation = np.uint8(resize(rgb2gray(processed_observation),
(FRAME_HEIGHT,FRAME_WIDTH))*255)
return np.reshape(processed_observation,(FRAME_HEIGHT,FRAME_WIDTH,1))
# (バッチ数,縦、横、状態数)
次にモデルを構築し、モデルを学習させるクラスを作成する。
BATCH_SIZE = 512
NUM_STORE_STATE = 50000
TRAIN_PER_GAME = 50000 // BATCH_SIZE
class PolicyEstimator():
def __init__(self, num_actions):
self.num_actions = num_actions
self.model = self.build_network()
self.state = tf.placeholder(tf.float32,
shape=(None,FRAME_WIDTH, FRAME_HEIGHT,STATE_LENGTH))
# self.action_probs = tf.placeholder(tf.float32, shape=(None, NUM_ACTIONS))
# 計算した確率
self.action = tf.placeholder(tf.float32, shape=(None, NUM_ACTIONS))
# とった行動のone_hot vector
self.target = tf.placeholder(tf.float32, shape=(None))
# self.loss = tf.placeholder(tf.float32, shape=(None))
self.action_probs = self.model(self.state)
self.log_prob = tf.log(tf.reduce_sum(self.action_probs * self.action))
# とった行動のときに予測してた確率
self.loss = -self.log_prob * self.target
self.optimizer = tf.train.AdamOptimizer(0.01)
self.minimize = self.optimizer.minimize(self.loss)
self.loss_list = []
self.replay_memory = {
'imgs':[],
'rewards':[],
'actions': [], # 実際にとったアクション
}
def build_network(self):
model = Sequential()
model.add(Conv2D(32, kernel_size=(8,8),strides=(4,4),activation='relu',
input_shape =(FRAME_WIDTH,FRAME_HEIGHT,STATE_LENGTH)))
model.add(Conv2D(64, kernel_size=(4,4),strides=(2,2),activation='relu',
padding='same'))
model.add(Conv2D(64,kernel_size=(3,3),strides=(1,1), activation='relu',
padding='same'))
model.add(MaxPooling2D(padding='same'))
model.add(Conv2D(128,kernel_size=(3,3),strides=(1,1),activation='relu',
padding='same'))
#model.add(Conv2D(128,kernel_size=(3,3),strides=(1,1),activation='relu',
# data_format='channels_first',padding='same'))
#model.add(Conv2D(256,kernel_size=(3,3),strides=(1,1),activation='relu',
# data_format='channels_first',padding='same'))
model.add(GlobalAveragePooling2D())
model.add(Dense(512,activation='relu'))
model.add(Dense(self.num_actions, activation='softmax')) # 最良の選択を行うので
print(model.summary())
return model
# ネットワークを学習させる関数を定義する。返り値は学習させたモデル
def train_network(self,imgs, rewards, actions):
optimizer = tf.train.AdamOptimizer(0.005)
reward_array = np.array(rewards)
# reward_array -= reward_array.mean()
reward_array /= 300.0
reward_array -= 2.0 # 全体を2だけシフトさせる
reward_list = reward_array.tolist()
if len(self.replay_memory['actions']) + len(actions) < NUM_STORE_STATE:
self.replay_memory['actions'] += actions
self.replay_memory['imgs'] += imgs
self.replay_memory['rewards'] += reward_list
elif len(self.replay_memory['actions']) < NUM_STORE_STATE:
# ストアする余白のある数
num_margin = NUM_STORE_STATE - len(self.replay_memory['actions'])
self.replay_memory['actions'] = \
self.replay_memory['actions'][num_margin:] + actions
self.replay_memory['imgs'] = \
self.replay_memory['imgs'][num_margin:] + imgs
self.replay_memory['rewards'] = \
self.replay_memory['rewards'][num_margin:] + reward_list
else:
# 十分にサンプル数がたまっている場合は全部押し出して良い。
num_sample = len(actions)
self.replay_memory['actions'] = self.replay_memory['actions'][num_sample:] + actions
self.replay_memory['imgs'] = self.replay_memory['imgs'][num_sample:] + imgs
self.replay_memory['rewards'] = self.replay_memory['rewards'][num_sample:] + reward_list
for i in range(TRAIN_PER_GAME):
num_memory = len(self.replay_memory['actions'])
rand_index = np.random.choice(range(STATE_LENGTH, num_memory),
BATCH_SIZE)
# 1回の学習に使う状態数は8つなので最初の7つは訓練用には使わない
img_train = []
reward = np.array(self.replay_memory['rewards'])[rand_index]
actions = np.array(self.replay_memory['actions'],dtype=np.int8)[rand_index]
for j in rand_index:
img_train.append(self.replay_memory['imgs'][j-STATE_LENGTH:j])
img_train = np.array(img_train)
img_train = img_train.transpose(0, 2, 3, 1, 4)
img_train = img_train.reshape(BATCH_SIZE, FRAME_HEIGHT,FRAME_WIDTH, STATE_LENGTH)
loss, _ = sess.run([self.loss, self.minimize],
feed_dict={self.target: reward, \
self.action: utils.to_categorical(actions, NUM_ACTIONS), \
self.state:img_train,
})
self.loss_list.append(loss.sum())
def load_weights(self,model_path):
self.model.load_weights(model_path)
def save_weights(self,model_path):
self.model.save_weights(model_path)
最後は学習を実行させるところ。
NUM_EPISODES = 1200 # 12000ゲーム分の記録を使って学習する
GAMMA = 0.99 # 報酬の減衰率
EPSILON_STEP = 10000000
EPSILON_DELTA = 0.8 / EPSILON_STEP
agent = PolicyEstimator(NUM_ACTIONS)
epsilon = 0.9
num_step = 0
sess = tf.Session()
sess.run(tf.global_variables_initializer())
score_list = []
for _ in range(NUM_EPISODES):
terminal = False
observation = env.reset()
reward_p = [] # ポイント間での報酬の値を入れるところ
reward_g = [] # ゲーム中の報酬の値を入れるところ
img_list = [] # ゲーム画面一覧を保存するところ
images = np.zeros((FRAME_HEIGHT,FRAME_WIDTH,STATE_LENGTH), dtype=np.uint8)
# 画像をSTATE_LENGTH個分入れておく
game_length = 0
action_list = []
last_ob = np.zeros((250,160,3),dtype=np.uint8)
flag = True
while not terminal:
env.render() # 画面の表示
if num_step < EPSILON_STEP:
epsilon -= EPSILON_DELTA
processed_img = preprocess(observation, last_ob)
last_ob = observation
images = np.concatenate((images[:,:,1:],processed_img),axis=2)
action_prob = agent.model.predict(images.reshape(1,FRAME_HEIGHT,FRAME_WIDTH,STATE_LENGTH))
if np.random.rand() > epsilon:
action = np.argmax(action_prob,axis=1)[0]
else:
action = env.action_space.sample()
action_list.append(action)
observation, reward, terminal, __ = env.step(action)
img_list.append(processed_img)
if reward == 0:
reward = 0.0
game_length += 1
elif reward > 0:
reward += 100.0
game_length = 0
score_list.append(1)
elif reward < 0:
reward -= 200.0
game_length = 0
score_list.append(0)
elif terminal: # ずっとサーブせずに試合が終了した場合
reward -= 1000.0
score_list.append(0)
reward_p.append(reward)
for i in range(len(reward_p)):
reward_p[len(reward_p)-i-1] += reward * GAMMA ** i
# 報酬を後ろの分にまで伝播させる。
if reward != 0.0 or terminal: # ポイントが決まったらreward_pを空にしてreward_gに結合
for x in reward_p:
reward_g.append(x)
reward_p = []
if flag and len(score_list)%500==0 and len(score_list)>0:
print(len(score_list), " Points score : ", np.mean(score_list[-500:]))
flag = False
num_step += 1
agent.train_network(img_list, reward_g, action_list)
# 1ゲームごとにモデルの更新を行う
if _ % 100 == 0 or _ == 10: # モデルの保存は100ゲームごと
agent.save_weights('./models/pg/pb_{}_weights.h5'.format(_))
if _ % 25 == 0:
print("{} Steps has done".format(num_step))
plt.subplot(121)
plt.plot(np.convolve(np.array(agent.loss_list)/BATCH_SIZE,np.ones(100)/100.0, mode='full'))
plt.title('Loss list in {} episodes'.format(_))
plt.subplot(122)
plt.plot(np.convolve(score_list, np.ones(500)/500.0,mode='full'))
plt.show()
結果
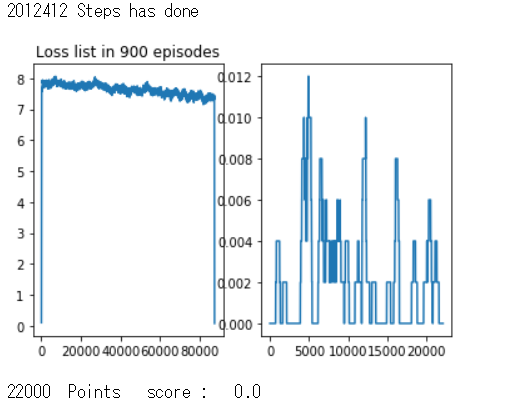
偶然の産物でポイントをとるものばかりで得点率が伸びる気配はなかった。
設定した損失(報酬の負の値)は徐々に減ってはいるもののこの時点ですでに24時間以上学習させていたのでいったん中断することにした。
勾配がなくならないよう、損失関数の値をあらかじめ2,3ほど足し合わせておくなどはした。

まとめ
今回は深層強化学習を使ってatariのテニスゲームに挑戦してみたが、DQN、方策勾配法のどちらでもうまくいかなかった。
ゲームの複雑さととりうる行動の多さから学習は困難と最初から予想してはいたが、失点を防ぐ動作を入れるのにもかなり苦労した。失点を防ぐように失点の際の損失を大きくするとずっとサーブを打たないという選択肢を取ることができてしまったので、そのような場合についても損失を加えるようなことはしていたがその分失点を防ぐようなラリーを学習できなかったのが残念。
パラメータチューニングがうまくいってない可能性もあるので、強化学習に関する本を読むなどして勉強してから再び挑戦できたらと思う。