今回紹介論文は音声認識のデータセットであるLibriSpeechでつい最近までSOTAを達成していたモデルについて扱った論文について読んでいるときに残したメモをここに置いておく。音声認識に興味あったので文字読み上げあたりはすっ飛ばしてしまっている。
(現在は他のモデルが1位を取得している)
A COMPARATIVE STUDY ON TRANSFORMER VS RNN IN SPEECH APPLICATIONS
ざっくりと概要
論文のタイトルは A COMPARATIVE STUDY ON TRANSFORMER VS RNN IN SPEECH APPLICATIONS 。
RNNベースのEncoder-DecoderモデルとEncoder-DecoderにTransformerを使ったモデルとを比較した論文。
音声認識に限らず音声翻訳(ST;Speech Translation)や文字読み上げ(TTS; Text to Speech)に応用している。
自然言語処理で世を席巻しているTransformerベースのモデルがついに音声認識側でもやってきたのがなかなか感慨深い。
しかも本当にそのままTransformerのEncoder-Decoder部分を使っているだけなので実装部分もシンプルっぽい。
今回のモデルも含めて様々な音声認識モデルを試せるレポジトリがあるので色々使ってみると良いと思う。
この論文は主著の方が日本人で苅田 成樹さんらしく、他にも著者の中に日本人の方が多数いる。
音声認識分野で日本人が実績出しているのをみるのはなんか嬉しい。
0. Abstract
- Transformerを用いたSequence-to-Sequenceのモデルの提案を行う
- 15の自動音声認識(ASR)のデータセットを用いて従来のRNNモデルとの比較を行った
- 2の文字読み上げ(TTS)のデータセットを使用
- Transformerの有用性を証明できた
- Kaldiスタイルでのコードも公開しており、学習に使用するデータもオープンソースのもの
コードはこちら
https://github.com/espnet/espnet
1. Introduction
- Transformerは自然言語処理(翻訳や内容理解)において非常に強力なモデル
- 今回はこれを音声認識、文字読み上げに適用したい。
Difficulties
- RNNベースのモデルに比べてより複雑な調整が必要となる
- optimizer
- ネットワーク構造
- data augmentation など
オープンソース化
- これまでは機械翻訳の文脈においてTransformerベースでオープンなデータを使って検証したものが存在していなかった
- 今回は誰でも利用できるようにオープンソースで行っていく
- TransformerとKaldiでうまく動いているHMMベースのRNNモデルの2つを使っていく
- 学習においてどのようなチューニングを行っていくかを詳細に取り扱う
論文のポイント
TransformerとRNNベースシステムにおいて様々な面から検証をした。
- TransformerとRNNにおいてASR関連のタスクにおいて大規模な比較実験を行い、大幅なパフォーマンスの向上を観測した
- ASR,TTS,音声翻訳(ST)においてTransformerモデルをどのように学習させるかを詳細に記した
- ESPnetを使って再現可能な学習コードを公開した
2. Sequence-to-Sequence RNN
2.1 Unified formulation for S2S
ソースシーケンス X からターゲットシーケンスである Y を出力するのがS2Sモデルの目的。
ASRにおけるS2Sモデルの共通した構造は以下の通り。
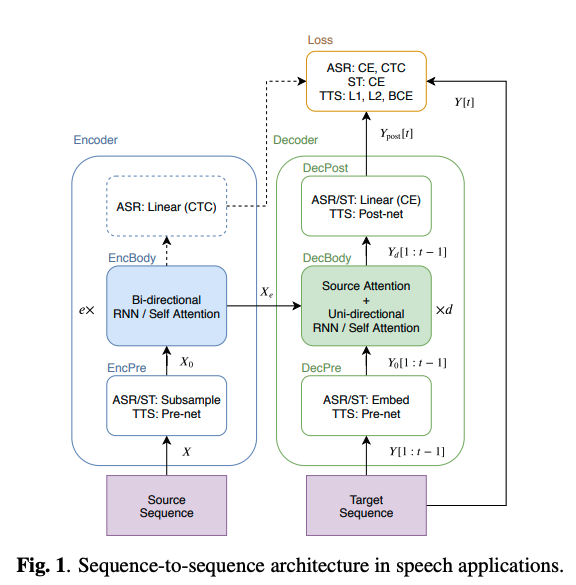
基本的には2つのモデル(Encoder,Decoder)から構成される。
- Encoder
X_e = EncBody(X_0) \tag{2}
- Decoder
Y_d[t] = DecBody(X_e, Y_0[1:t-1]) \tag{4}
Y_{post} [1:5] = DecPost(Y_d[1:t]) \tag{5}
- $e$ : EncBodyでの層の数
- $d$ : DecBodyでの層の数
- $t$ : ターゲットフレームのインデックス
$$
- $Y_{post}$ : 生成されたシーケンス
- $Y$ : ターゲットとなるシーケンス
2.2 RNN encoder
式(2)でのEncBody(・)がソースシーケンスである X_0 を内部表現 X_e に変換する。
- Bi-LSTM (双方向LSTM)がよく使われる
- CTC(Connectionist temporal classification)を使えば学習とデコーディングを同時に行える
2.3 RNN decoder
式(4)でのDecBody(・)はエンコードされたシーケンス X_e と直前までの出力(もしくはGroudn Truth) Y_0[1:t-1] を使って次の出力を予測する。
- Attention機構つきのUni-LSTM(単方向LSTM)
- Attention機構はフレーム方向の重みをつけて足し合わせを行う
- エンコードされたソースシーケンスである X_e をフレーム方向に局所的に足し合わせを行ってしまう
このタイプのAttentionを “encoder-decoder attention”と呼ぶ。
3. Transformer
Transformerはシーケンスの情報をself-Attentionと呼ばれる機構を使って抽出する。
3.1 Multi-head attention
$$
- $X^k, X^v \in \mathbb{R}^{n^k\times d^att}$ : キー、バリュー
- $X^q \in \mathbb{R}^{n^q\times d^att}$ : クエリー
- $d^{att}$ : 特徴量の次元数
H_h = att(QW_h^q, KW_h^k, VW_h^v) \tag{9}
$$
- $K,V \in \mathbb{R}^{n^k\times d^{att}}$ : キーとバリュー
- $Q \in \mathbb{R}^{n^q \times d^{att}}$ : クエリー
- $H_h\in \mathbb{R}^{n^q \times d^{att}}$ : $h$ 番目のattention layerの出力
- $W^q_h, W^k_h, W^v_h \in \mathbb{R}^{d^{att}\times d^{att}}$ : 学習対象の変換行列。
- $W^{head} \in \mathbb{R}^{d^{att}d^{head}\times d^{att}}$ : 計算されたAttentionの値同士を線形変換するための行列。学習の対象。
3.2. Self-attention encoder
X_{i+1} = X_i’ + FF_i(X_i’) \tag{10}
$$
- $i=0,\cdots, e-1$ はエンコーダ層のインデックス
FF_i : i番目の2層のフィードフォワードネットワーク
FF(X[t]) = ReLU(X[t]X^{ff}_1 + b^{ff}_1) W_2^{ff} + b_2^{ff} \tag{11}
- $X[t]\in \mathbb{R}^{d^{att}}$ : 入力シーケンス $X$ の$t$ 番目のフレーム
- $X_1^{ff}\in \mathbb{R}^{d^{att}\times d^{ff}}, W_2^{ff}\in \mathbb{R}^{d^{ff} \times d^{att}}$ : 学習対象の重み行列
- $b_1^{ff} \in \mathbb{R}^{d^{ff}}, b_2^{ff}\in \mathbb{R}^{d^{att}}$ : 学習対象のバイアスベクトル
MHA_i(X_i, X_i, X_i) を ‘self-attention’と呼んでいる。
3.3. Self-attention decoder
Y_j” = Y_j + MHA_j^{src}(Y_j’, X_e, X_e)
Y_{j+1} = Y_j” + FF_j(Y_j”) \tag{12}
$$
- $j=0,/cdots,d-1$ : デコーダ層のインデックス
- $MHA_j^{src}(Y_j’, X_e, X_e)$ を’encoder-decoder attention’と呼ぶ
3.4 Positional Encoding
時間的な位置を示すため、Positional Encodingと呼ばれる値を入力に結合する。
PE[t] = \begin{cases} sin\frac{t}{10000^{t/d^{att}}}&if\ t\ is\ even \\
cos\frac{t}{10000^{t/d^{att}}}&if\ t\ is\ odd
\end{cases}
入力シーケンスである Y_0, X_0 は DecBodyやEncBodyに入力される前にPE[1], PE[2], ….と結合される。
4. ASR Extensions
log-メルスペクトログラムに該当する入力シーケンス X^{fbank} (fbankはフィルターバンクの意味)から文字かSentencePieceレベルでのターゲットシーケンスである Y を出力させるように学習させた。
4.1 ASR encoder architecture
X は83次元のlog-メルスペクトログラム
- 2層、256チャンネル、カーネルサイズ3、ストライド2のCNNを使って X_0 \in \mathbb{R}^{n^{sub}\times d^{att}} に変換する
- $n_{sub}$ はCNNが出力するシーケンスの長さなので元の Xよりも短いものとなっている
これをEncPre(・)とする
EncBody(・)は変換された X_0 を X_e\in \mathbb{R}^{n^{sub}\times d^{att}} に変換し、CTCやデコーダネットワークへと渡す
4.2. ASR decoder architecture
デコーダネットワークが受け取るのは以下の2つ
- エンコードされたシーケンス X_e
- 直前までのターゲットシーケンス Y[1:t-1] (文字かSentencePieceでのIDが格納されている)
まずは
– DecPre(・)によってトークンを学習可能なベクトルの形に埋め込みをする
– DecBody(・)と1層の線形結合層であるDecPost(・)を使って次のトークンの事後確率分布である Y_{post}[t] を計算する。
4.3. ASR training and decoding
decoderもCTCも 入力シーケンスであるXが与えられた時の Yの事後確率を予測する。
- $p_{s2s}(Y|X)$
- $p_{ctc}(Y|X)$
損失関数は以下のように設定した。
L^{ASR} = -\alpha log p_{s2s}(Y|X) – (1-\alpha)log p_{ctc}(Y|X) \tag{14}
- $\alpha$ : ハイパーパラメータ
デコード段階では、S2S,CTCそしてRNNの言語モデルで出されたスコアの組み合わせからビームサーチを使って予測する。
\hat{Y} = arg \max_{Y\in \mathcal{Y}}(\lambda log p_{s2s}(Y|X_e) + (1-\lambda)log p_{ctc}(Y|X_e) +
\gamma log p_{lm}(Y))\tag{15}
- $\mathcal{Y}$ : ターゲットシーケンスの候補となっているシーケンスの集合
- $\gamma,\lambda$ : ハイパーパラメータ
5. ST Extensions
割愛
CTCは使わなかったけど、基本はASRと同じ
6. TTS EXtensions
割愛
7. ASR Experiments
7.1 Dataset
- 15個のデータセットを使用
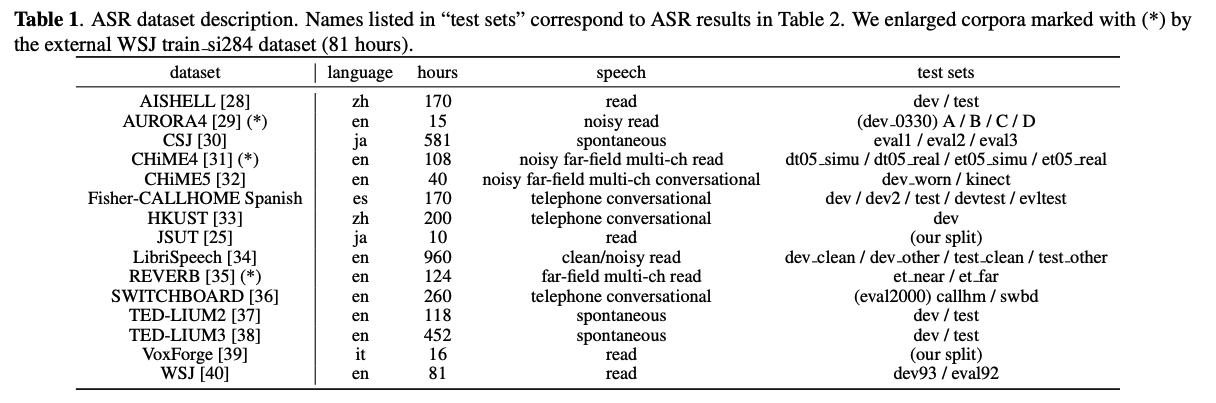
- 一部のデータセット(CSJ, CHiME4, Fisher-CALLHOME Spanish, HKUST, TED_LIUM2/3)に対してはスピードを0.9,1.0,1.1倍に変更してデータのカサましをした
- 他のデータセット(Aurora4, LibriSpeech, TED-LIUM2/3, WSJ)についてはSpecAugmentを施した(スペクトログラムに一部マスキングを施す)
7.2 Settings
オリジナルのTransformerと同じ構造を用いた。
- $e=12$
- $d=6$
- $d^{ff}=2048$
- $d^{head}=4$
- $d^{att}=256$
LibriSpeechだけデータセットが大きかったので d^{head}=8,d^{att}=512 に変更した。
RNNの構造についてはこれまでの研究から最もうまくいった設定を使用した
Optimizer
- RNNに対しては Adadeltaとearly stoppingを使った
- TransformerはRNNとは異なったものを使用する必要がある
- RNNよりも学習が収束するのが早く、微調整の幅が細かいため
- dropout
- 学習率
- warmup step は使用
- early stoppingは使用しなかった
- Epoch数は20-100(基本的には100Epoch)
- 最後の10エポック分のモデルのパラメータを保存しておき、それらの平均値を最終的な出力とした。
GPUの枚数
1枚で実験を行っていった
Decoder
各々のコーパスにおいてRNNとTransformerは同じ設定を共有した
- ビーム幅 : 20-40
- CTCの重み \lambda : 0.3
- 言語モデルの重み \gamma : 0.3-1.0
7.3 Results
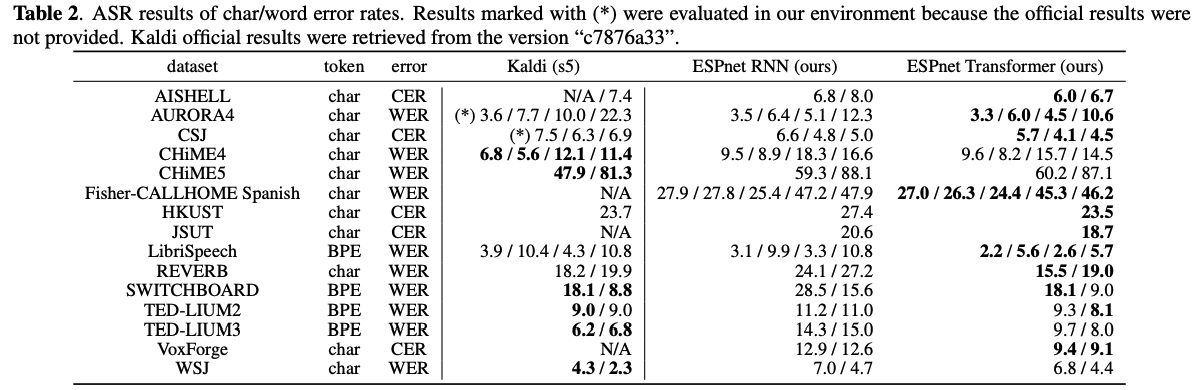
各々のコーパスにおけるスコアは以上のようになった。
日本語データセット(CSJ)においてはKaldiの精度を上回っている。(素晴らしい)
全体的に、RNNよりかはTransformerベースのネットワークを使った方がより良い結果が出ていることがわかる。
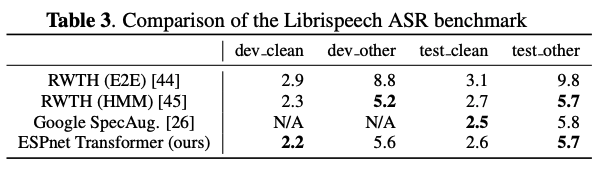
上の表はLibrispeechにおけるスコアの比較をしている。
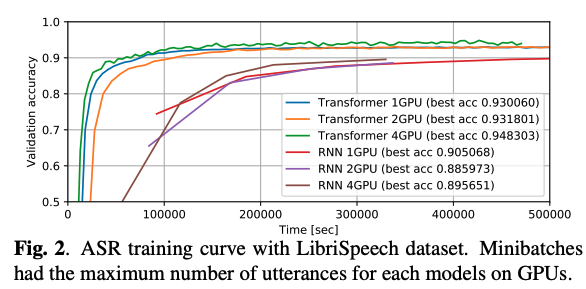
上のグラフはGPUの枚数とTransformer、RNNで実行時間をスコアの上昇推移を比べたものである。
GPUを4つ使い、バッチサイズを大きくした方が学習がよりよく進むことがわかった。
7.4 Discussion
学習を進める上で得られた知見を挙げていく
- Transformerがなかなか学習が進まなかったらバッチサイズを上げてみる
- 学習時間も短くなるし、精度も向上するので良いことづくめ
- accumulating gradient strategyを使ってMulti GPUにおけるバッチサイズの向上を行うことは有効
- RNNではdropoutは有効ではなかったが、Transformerでは必須。
- いくつかのdata augmentationメソッドを使用したが、有効に働いた
- $\gamma,\lambda$ はRNNとTransformerのどちらにおいても同じ値が最も適切だった
8. Multilingual ASR Experiments
9. Speech Translation Experiments
10. TTS Experiments
11. Summary
TransformerベースのモデルとRNNベースのモデルの比較をASR(15のタスク)、ST(1コーパス)、TTS(2つのコーパス)において行った。
結果としては非常に今後に期待ができるものとなり一部のタスクでは大幅な精度向上を実現することができた。