「ゼロから作るDeep Learning 2 自然言語処理編」を読んで、Word2VecのモデルをsentencepieceとTensorFlowを使用して日本語でも実装できるんじゃないかと思い立ったのでやってみる。
残念ながら、学習がうまく進まなかったのでひとまず公開だけしておき、学習が進んだらまた記事を更新したいと思う。
(追記2020年2月12日)
学習がうまく進んだので変更分はgithubに全面的に反映させた。
実装はこちら
https://github.com/wildgeece96/word2vec
Word2vecについて
Word2vecというのは単語をベクトル表現にと落とし込むのこと。
今回は、continuous bag-of-words(COBW)と呼ばれる手法を使ってベクトル表現をニューラルネットワークに学習させていく。
CBOWの基本的な理念
COBWでは、くり抜いた単語の、前後W単語(Wは任意の自然数)の合計2W単語から、くり抜かれた単語を予測しにいくタスクを解いていくことによって単語の内部表現を獲得しにいくモデルを指す。
It is none of your businesss.
があったとする。
この時、none という単語をマスキングして、
It is [mask] of your business.
W=2として、前後2単語("it", "is", "of", "your")から"[mask]"の単語を予測する。
これを、中間層ありの2層のニューラルネットワークで実装する。
ネットワーク構造
各層の解釈は以下の通り。
- 1層目で前後2W単語の分散表現を獲得し、足し合わせる
- 2層目獲得された分散表現から、マスクされた単語を予測する
まず、1層目では以下の式で表されるように、各単語に該当する暫定ベクトルを抜き出してその平均を取得する。ここでは i 番目の入力について考える。
(1) ![$$ h_{vec} = \frac{1}{N}\sum_{v \in \mathcal{V_i}} W_{vec}[v] + \boldsymbol{b}_{vec} $$](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-4dcd5adf517037c29852900aa9f92e78_l3.png "Rendered by QuickLaTeX.com")
- $\mathcal{V}_i$ : 単語の集合。添字 $i$ は$i$番目の入力に該当する単語の集合を示す。
- $W_{vec} \in \mathbb{R}^{|\mathcal{V}|\times H}$ : 各単語に該当するベクトルを保存する重み行列
- $\boldsymbol{b}_{vec}\in \mathbb{R}^H$ : バイアスベクトル
- $H$ : ベクトルのサイズ
二層目では、得られた表現にまた線形変換を行いそこにソフトマックス(Negative Samplingを使用するときはシグモイド関数)をかけた値で各語彙に対する確率を計算する。
語彙数が膨大になる時、全部の出力結果を考慮すると計算量が多くなってしまうため答えに関係するものだけ考慮する場合がある。この時はシグモイド関数を活性化関数とし、正例といくつかの負例のみの確率を最適化する手法が存在する。
これをNegative Samplingと言う。
p_{v_y} = Sigmoid(h_{vec} W_{out}[v_y] + \boldsymbol{b}_{out})
- $v_y$ : 今回マスキングされた単語に該当する語彙
- $W_{out}\in \mathbb{R}^{H\times |\mathcal{V}|}$ : デコード用の重み行列
ただ、これだけ計算して誤差逆伝播をしてしまうと全ての出力を高くしておけば問題ないということになってしまう。
そのため、負例についてもいくつかコーパスの頻度分布にしたがってランダムに入れ込み、それらについては確率がゼロになるように計算させる。
p_{v_{neg}} = Sigmoid(h_{vec} W_{out}[v_{neg}] + \boldsymbol{b}_{out})
これを何単語入れるかは計算機の実力次第。
これらの確率からクロスエントロピー誤差を獲得して誤差逆伝播させていく。
Negative Samplingを使わない場合は単純なエントロピー誤差のみを計算すれば良くなり、
\boldsymbol{p} = Softmax(\boldsymbol{h_{vec}} W_{out})
L = – \boldsymbol{y} log(\boldsymbol{p}) \
- $\boldsymbol{y}\in \mathbb{R}^{V}$ : one-hotベクトル
実装
では実際に実装していく。
以下でおいていくコードはこのレポジトリに全ておいてある。
https://github.com/wildgeece96/word2vec
sentencepiceの学習ずみTokenizerも置いてある。
データセットの用意
日本語Wikipediaでもよかったが時間がかかりそうだったので青空文庫の小説をとってきてそれらを学習に回すことにした。
まずはダウンロードできる作品リストを取得する。
mkdir data
wget https://www.aozora.gr.jp/index_pages/list_person_all_extended_utf8.zip -P data
unzip data/list_person_all_extended_utf8.zip
mv list_person_all_extended_utf8.csv data/list_person_all_extended_utf8.csv
取得したCSVファイルの情報を元に、テキストファイルをダウンロードしていく。
csvファイルを ./data/list_person_all_extended_utf8.csv に入れたときに、joblibを使って並列処理でダウンロードする。
若干作品数が多かったので並列処理で行うことにした。
import pandas as pd
import os
import subprocess as sub
from tqdm import tqdm
from joblib import Parallel, delayed
df = pd.read_csv("./data/list_person_all_extended_utf8.csv")
df = df[df["作品著作権フラグ"] == "なし"] # 著作権のない作者だけ抜き出す
urls = df['テキストファイルURL']
os.makedirs("./data/zip", exist_ok=True)
os.makedirs("./data/text", exist_ok=True)
def download_zip(url):
devnull = open('/dev/null', 'w')
cmd = ["wget", url, "-P", "data/zip"]
sub.Popen(cmd, stdout=devnull, stderr=devnull)
save_path = os.path.join('data/zip/', url.split('/')[-1])
unzip_cmd = ["unzip", save_path, "-d", "./data/text"]
sub.Popen(unzip_cmd, stdout=devnull, stderr=devnull)
devnull.close()
results = Parallel(n_jobs=5, verbose=10)(delayed(download_zip)(str(url)) for url in urls)
次に、純粋な本文のみを取り出すために前処理を行う。
青空文庫はルビを籠城《ろうじょう》の一揆軍は全滅したと伝えられ丁寧につけてくれているのだが今回はいらない。
そのため、簡単な正規表現を使って<<**>> を抜き出していく必要がある。
また、最初と最後に書籍情報を掲載しているところが10行ほど存在しているのでそこも削除する。
import glob
import re
from tqdm import tqdm
text_paths = glob.glob("./data/text/*.txt")
regex_1 = re.compile("《.*?》|\[.*?\]")
def remove_rubi(lines):
new_lines = [regex_1.sub("", line) for line in lines]
return new_lines
symbol = "--------------------------------------------"
def remove_explanation(lines):
separate_symbol_cnt = 0
new_lines = []
for line in lines:
if separate_symbol_cnt < 2 and symbol in line:
separate_symbol_cnt += 1
continue
elif separate_symbol_cnt >= 2:
new_lines.append(line)
if separate_symbol_cnt == 0:
return lines
return new_lines
def remove_information(lines):
# 後ろから文章を見ていって、改行記号のみの行が2つ見つかるまでの範囲は文書情報とみなして削除する
n_cnt = 0
idx = 0
for i, line in enumerate(lines[::-1]):
if i == 0:
continue
elif line == "\n":
n_cnt += 1
if n_cnt >= 1:
idx = i
break
lines = lines[:-idx]
return lines
def remove_blank_lines(lines):
new_lines = []
for line in lines:
if line != "\n":
new_lines.append(line)
return new_lines
exception_cnt = 0
for text_path in tqdm(text_paths):
try:
with open(text_path, "r", encoding='sjis') as f:
lines = f.readlines()
lines = remove_rubi(lines)
lines = remove_explanation(lines) # 文頭部分の説明文の削除
lines = remove_information(lines) # 文末部分の説明文の削除
lines = remove_blank_lines(lines)
with open("./data/corpus.txt", "a") as f:
f.writelines(lines)
except:
exception_cnt += 1
print(f"{exception_cnt:04d} exdeptions has occurred.")
とりあえずこれでコーパスの用意は完了した。
Sentencepieceを使ったTokenizerの学習
今回は英語ではなく、日本語を使うので分かち書きをするのが少々難しい。
sudachi などを使ってやるのもよかったが、以前にも使ったsentencepieceを使おうと思う。
sentencepieceを以前使った記事はこちらにある
import sentencepiece as spm
sp = spm.SentencePieceProcessor()
spm.SentencePieceTrainer.Train("--input=./data/corpus.txt \
--model_prefix=tokenizer/aozora_8k_model \
--vocab_size=8000 --character_coverage=0.98 \
--shuffle_input_sentence=true")
簡単な動作確認をする。
import sentencepiece as spm
sp = spm.SentencePieceProcessor()
sp.Load('tokenizer/aozora_8k_model.model')
text="僕の周りには分からないことだらけだけれど、1つずつ理解していくような努力をしていきたいと思う。"
print(sp.EncodeAsPieces(text))
出力結果
['▁', '僕の', '周', 'り', 'には', '分', 'から', 'ないこと', 'だらけ', 'だ', 'けれど', '、', '1', 'つ', 'ずつ', '理解', 'して', 'いく', 'ような', '努力', 'をして', 'いき', 'たい', 'と思う', '。']
前回と似たような結果になったのである程度うまく学習できた様子。
トークンの頻度分布を確かめる
今度はトークンごとの頻度を取得する必要がある。
この頻度分布がないとNegative Samplingがうまくいかないと思われるため。
import sentencepiece as spm
import numpy as np
import os
from tqdm import tqdm
sp = spm.SentencePieceProcessor()
sp.load("./tokenizer/aozora_8k_model.model")
vocab_size = sp.get_piece_size()
x_hist = np.zeros(vocab_size, dtype=np.float64)
with open("./data/corpus.txt", "r") as f:
corpus = f.readlines()
for line in tqdm(corpus):
ids = sp.EncodeAsIds(line)
for id in ids:
x_hist[id] += 1
x_hist /= x_hist.sum()
x_dist = x_hist*0.95 + 0.05/8000
os.makedirs("./out", exist_ok=True)
np.save("./out/x_dist.npy", x_hist)
レイヤー設計
まずは1層目の埋め込み部分から。
ここはkerasですでに実装されているEmbeddingレイヤーを使う。
Embeddingレイヤーでの出力を平均する必要があったのでその操作までを含めてContextEmbeddingLayerと名付けた。
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.layers import (
Embedding
)
class ContextEmbeddingLayer(keras.layers.Layer):
def __init__(self, vocab_size, hidden_dim, input_length=10):
super(ContextEmbeddingLayer, self).__init__()
self.embedding = Embedding(vocab_size, hidden_dim, input_length=input_length)
def call(self, inputs):
x = self.embedding(inputs)
x = tf.reduce_mean(x, axis=1)
return x
NegativeSamplingは結局実装しなかった。
厳密には、実装したがうまくいきそうになかったのでやめたという表現が正しい。
一応その残骸をここに載せておく。
class NegativeSamplingLayer(keras.layers.Layer):
def __init__(self, hidden_dim, vocab_size, num_sample=5):
super(NegativeSamplingLayer, self).__init__()
self.out_embedding = Embedding(vocab_size, hidden_dim, input_length=5)
self.num_sample = num_sample
def call(self, inputs, idxs):
'''
inputs : (batch_size, hidden_size).
idxs : (batch_size, num_sample).
'''
negative_embed = self.out_embedding(idxs)
# (batch_size, num_sample, hidden_dim)
negative_embed = tf.transpose(negative_embed, perm=[0, 2, 1])
# (batch_size, hidden_dim, num_sample)
x = tf.matmul(inputs, negative_embed)
x = tf.math.sigmoid(x)
return x
上記2つのレイヤーをまとめたCBOWモデルクラスを実装。
num_neg_samplesは、Negatvie Samplingを行う数+1の値。
class CBOW(keras.Model):
def __init__(self, hidden_dim=100, vocab_size=8000, window_size=5, num_neg_samples=10):
super(CBOW, self).__init__()
self.embedding = ContextEmbeddingLayer(vocab_size, hidden_dim, window_size*2)
self.negatvie_sampling_dot = NegativeSamplingLayer(hidden_dim, vocab_size, num_samples=num_neg_samples)
def call(self, inputs, negative_samples):
"""
inptus : tf.Tensor. (batch_size, window_size*2).
negative_samples : tf.Tensor. (batch_size, num_neg_samples).
"""
x = self.embedding(inputs)
x = self.negative_sampling_dot(x, negative_samples)
x = tf.math.sigmoid(x)
return x
DataLoaderの実装
DataLoaderもコードだけ置いておく。
class DataLoader(object):
def __init__(self, window_size, neg_sample_num,
corpus_path="./data/corpus.txt",
sp_path="./tokenizer/aozora_8k_model.model"):
self.sp = spm.SentencePieceProcessor()
self.sp.load(sp_path)
self.corpus_path = corpus_path
self.window_size = window_size
self.neg_sample_num = neg_sample_num
self.vocab_size = self.sp.get_piece_size()
def load(self, x_dist, batch_size=100, shuffle=True):
with open(self.corpus_path, "r") as f:
lines = f.readlines()
batch = []
y = []
while True:
if shuffle:
random.shuffle(lines)
for line in lines:
ids = self.sp.EncodeAsIds(line)
if len(ids) < self.window_size*2+1:
continue
_batch, _y = self.make_batch(ids)
batch += _batch
y += _y
while len(batch) >= batch_size:
# negative_samples = np.random.choice(range(self.vocab_size),
# size=(batch_size,self.neg_sample_num),
# p=x_dist)
# negative_samples[:, 0] = y[:batch_size]
yield (tf.convert_to_tensor(batch[:batch_size], dtype=tf.int32),
tf.convert_to_tensor(y[:batch_size], dtype=tf.int32))
batch = batch[batch_size:]
y = y[batch_size:]
def make_batch(self, ids):
w_size = self.window_size
mini_batch = []
y = []
for i in range(w_size, len(ids)-w_size):
_ids = ids[i-w_size:i] + ids[i+1:i+w_size+1]
mini_batch.append(_ids)
y.append(ids[i])
return mini_batch, y
Trainerの実装
学習を実行するクラスTrainerをここで実装する。
損失の計算部分もここに実装してしまった。(本当は別途で関数を設けるべきであったが。。)
import tensorflow as tf
import tensorflow.keras as keras
from tqdm import tqdm
import numpy as np
import datetime
class Trainer(object):
def __init__(self, model, loader, x_dist, optimizer):
self.model = model
self.bce = tf.nn.softmax_cross_entropy_with_logits
self.loader = loader
self.neg_sample_num = self.loader.neg_sample_num
self.x_dist = x_dist
self.optimizer = optimizer
def train(self, batch_size, epochs=10):
self.batch_size = batch_size
self.time = datetime.datetime.now().strftime("%Y%m%d-%H%M")
self.writer = tf.summary.create_file_writer(f"./out/record/{self.time}")
for epoch in range(epochs):
self.train_epoch(epoch, epochs)
self.save_model(epoch)
def train_epoch(self, epoch, epochs):
with tqdm(self.loader.load(self.x_dist, self.batch_size)) as pbar:
pbar.set_description(f"[Epoch {epoch:02d}/{epochs:02d}]")
for i, (batch, ys) in enumerate(pbar):
loss_value, _ = self.train_step(batch, ys)
with self.writer.as_default():
tf.summary.scalar("loss", loss_value.numpy(), step=i)
self.writer.flush()
pbar.set_postfix({"loss" : loss_value.numpy(), "samples" : i*self.batch_size})
def train_step(self, inputs, ys):
with tf.GradientTape() as tape:
loss_value = self.loss(inputs, ys)
grads = tape.gradient(loss_value, self.model.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_weights))
return loss_value
def loss(self, inputs, ys):
logits = self.model(inputs)
y = np.zeros([self.batch_size, logits.shape[-1]], dtype=np.float32)
for i, _idx in enumerate(ys):
y[i, _idx] = 1
y = tf.convert_to_tensor(y, dtype='float32')
loss = tf.reduce_sum(- y * logits)/self.batch_size
return loss, logits
def save_model(self, epoch):
save_path = f"./out/record/{time}/model_{epoch:03d}.h5"
model.save(save_path)
学習
ではこれらを実装したもので学習を行う。
CPUだと半日くらいかかりそうなのでGPUに計算を任せることにする。
大体1時間くらいで終わった。
lossの経過をTensorboardでみてみる。
tensorboard --logdir ./out/record/20200211-0111
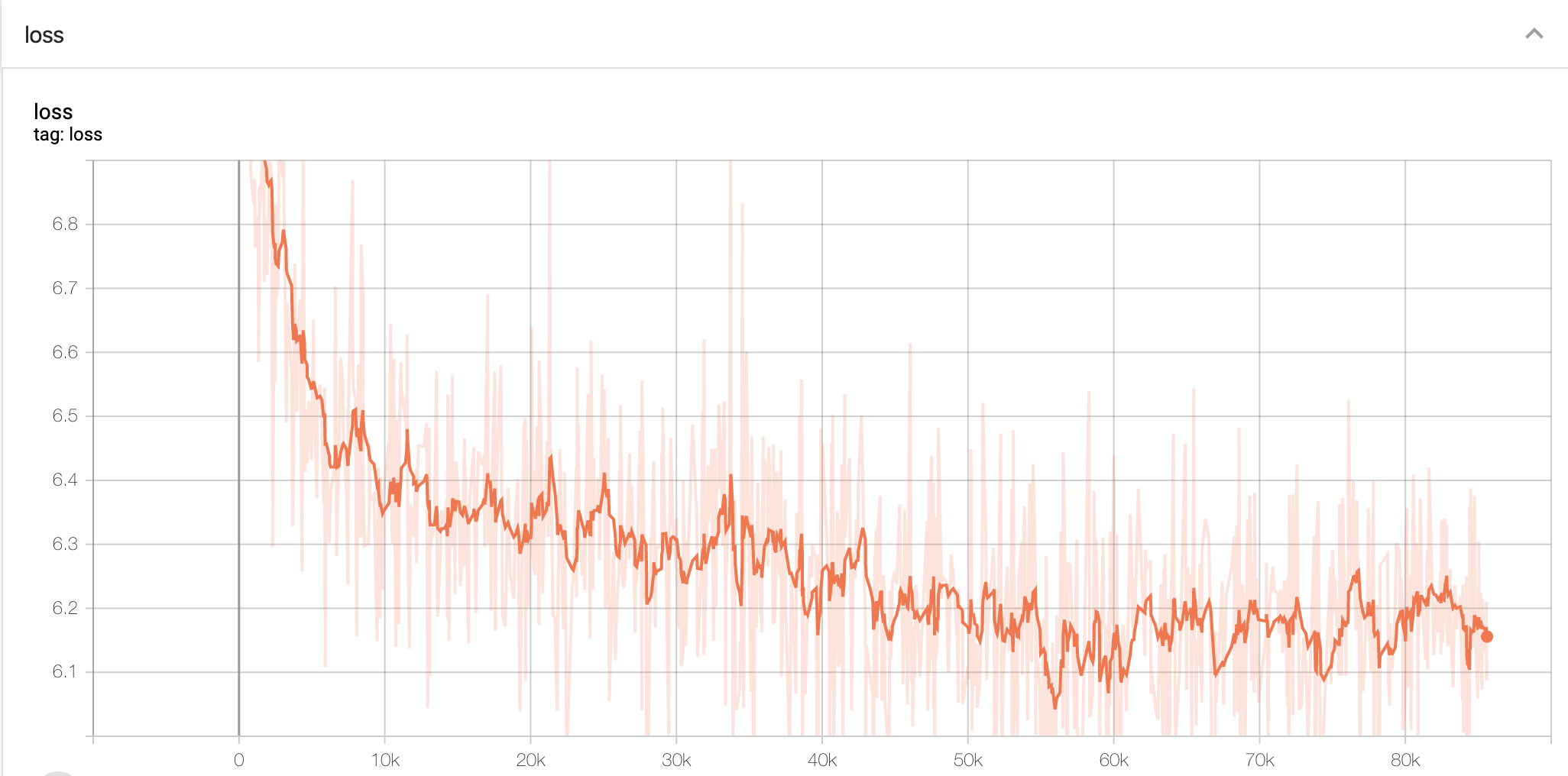
指定したハイパーパラメータは以下の通り。
(05_train.py参照)
window_size = 5
hidden_dim = 100
batch_size = 1000
epochs = 20
corpus_path = "./data/corpus.txt"
sp_path = "./tokenizer/aozora_8k_model.model"
10エポック目(45kステップ目くらい)で学習率を1/10に縮小した。
Negative Samplingは結局使用せず、Softmαxで全体の確率を出力するようにした。
中身の確認
学習させたベクトルをいくつかみていきたいと思う。
以下のコードを app/06_eval.py の名前で保存。
import sys
import numpy as np
import sentencepiece as spm
import matplotlib.pyplot as plt
# Evaluate the vectors.
vec_path = sys.argv[1]
# e.g. ./out/record/20200211-1011/wordvec_009.npy
sp_path = "./tokenizer/aozora_8k_model.model"
sp = spm.SentencePieceProcessor()
sp.load(sp_path)
word_vec = np.load(vec_path)
print("Enter the word")
string = input()
ids = sp.EncodeAsIds(string)
def find_similar(id, word_vec, topn=5):
query_vec = word_vec[id][:, np.newaxis]
# normalize vectors
word_vec /= np.sqrt(np.power(word_vec, 2).sum(axis=1, keepdims=True))
cosine = np.dot(word_vec, query_vec).flatten()
# most similar word is the same word for id.
most_similar_ids = np.argsort(cosine)[-2-topn:-1]
print("Original word : ", sp.DecodeIds([id]))
for i in range(topn):
print(f"\tTop {i:02d} : ", sp.DecodeIds([int(most_similar_ids[-2-i])]))
for id in ids:
find_similar(id, word_vec, topn=5)
こんな感じで、起動し、適当な文章を打ってみると、それに類似した単語が5個くらい表示される。
python app/06_eval.py ./out/record/20200211-1146/wordvec_009.npy
Enter the word
吾輩は猫である
Original word :
Top 00 : この
Top 01 : そして
Top 02 : ――
Top 03 : ......
Top 04 : ――
Original word : 吾
Top 00 : 我が
Top 01 : 我
Top 02 : われ
Top 03 : 己
Top 04 : 此
Original word : 輩
Top 00 : 友
Top 01 : 知りません
Top 02 : 生きた
Top 03 : 言
Top 04 : モノ
Original word : は
Top 00 : はまた
Top 01 : はもう
Top 02 : は皆
Top 03 : はまだ
Top 04 : 人は
Original word : 猫
Top 00 : 洋服
Top 01 : 犬
Top 02 : 幽霊
Top 03 : 女中
Top 04 : 僕等
Original word : である
Top 00 : です
Top 01 : だった
Top 02 : でした
Top 03 : なのである
Top 04 : となった
結果を見てみると、ある程度できていそうな雰囲気はあるがそもそも区切り方自体に意味が含まれにくいため、うまく学習できていないものもある。
であるや猫、吾あたりは結構近い単語が出ている気がする。
lossが思ったより下がりきらなかったので少々不安であったが結構面白い結果になったと思う。