今参加中のKaggleのコンペティションでは衛星が取得した画像から船を検知するもの。
コンペティションのリンクはこちら
ここのコンペティションで使われているモデルとして最有力候補なのがUNetと呼ばれるもの。
具体的にどんな場面で使われているのか、どんなネットワーク構造を持っているのかがよく分からなかったので調べてみることに。
U-Netとは
そもそもは医療用の画像検知のために使われたのが最初らしい。
細胞のセグメンテーションとかやってるっぽい。
2015年のISBIでの細胞検知チャレンジでかなり良い成績を残した。
こんなことができる。
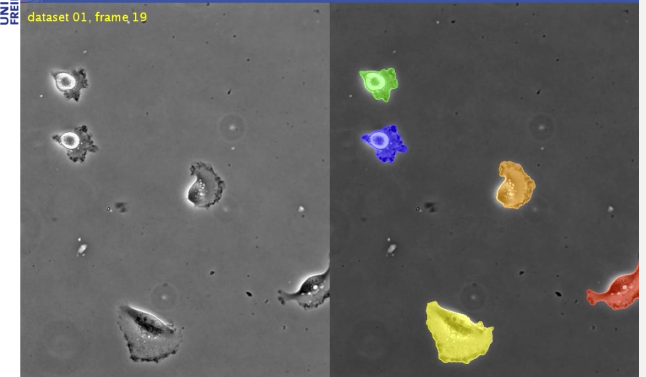
学習時間が短く(10時間ほど)、実用場面でもGPUを使うなら1秒程度でできるというのも特徴。
以下のサイトの動画で成果をわかりやすくまとめているのでみてみると凄さがわかると思う。
U-Net: Convolutional Networks for Biomedical Image Segmentation
Caffeを使った学習済みのデータも公開している。
ネットワーク構造
どんなネットワーク構造になっているのか。
この画像が全てを物語っている。

https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ より
この画像では入力が572×572のものでそれを2層の畳み込み層を通過し、max-poolで画像を縮小して。。。というのを4回繰り返してる。
全結合層を一切使わず、畳み込み層のみで全てを構成。
パッディングしないのも特徴。なので1回ごとに畳み込みを適用すると出力される画像が少しだけ小さくなる。
4回ダウンサンプリングするので画像サイズは1/256になる。
ダウンサンプリングが終われば今度はアップサンプリング。
U-Netの特徴はここでダウンサンプリングの時に使っていた出力をそのままアップサンプリングした後の入力に合流させているところ。(論文だとどうしてそうしたのかは明記されてなかった)
学習の進め方
損失関数はどうやらクロスエントロピーで最終的に求めているようだ。
最後の出力がソフトマックスを選んでいる影響が強そう。
ダウンサンプリングするときの最後のとことろでDrop-outを入れると有効みたい。
これはKaggleにも使えそうな手法。
教師データを増やすために画像自体の変形を10ピクセルでの標準偏差を持つガウシアン分布を元におこなっている。(この辺り論文読んでもよく分からなかった)
他にはグレースケールの変更もしていた。
Pytorchでの実装
他のところからのコピペだけど貼るだけ貼っておく。
ソースコードはここから拾ってきた。
https://github.com/GunhoChoi/Kind-PyTorch-Tutorial/tree/master/12_Semantic_Segmentation
import torch
import torch.nn as nn
import torch.utils as utils
import torch.nn.init as init
import torch.utils.data as data
import torchvision.utils as v_utils
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.autograd import Variable
def conv_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.Conv2d(in_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def conv_trans_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.ConvTranspose2d(in_dim,out_dim, kernel_size=3, stride=2, padding=1,output_padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def maxpool():
pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
return pool
def conv_block_2(in_dim,out_dim,act_fn):
model = nn.Sequential(
conv_block(in_dim,out_dim,act_fn),
nn.Conv2d(out_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
)
return model
def conv_block_3(in_dim,out_dim,act_fn):
model = nn.Sequential(
conv_block(in_dim,out_dim,act_fn),
conv_block(out_dim,out_dim,act_fn),
nn.Conv2d(out_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
)
return model
class UnetGenerator(nn.Module):
def __init__(self,in_dim,out_dim,num_filter):
super(UnetGenerator,self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.num_filter = num_filter
act_fn = nn.LeakyReLU(0.2, inplace=True)
print("\n------Initiating U-Net------\n")
self.down_1 = conv_block_2(self.in_dim,self.num_filter,act_fn)
self.pool_1 = maxpool()
self.down_2 = conv_block_2(self.num_filter*1,self.num_filter*2,act_fn)
self.pool_2 = maxpool()
self.down_3 = conv_block_2(self.num_filter*2,self.num_filter*4,act_fn)
self.pool_3 = maxpool()
self.down_4 = conv_block_2(self.num_filter*4,self.num_filter*8,act_fn)
self.pool_4 = maxpool()
self.bridge = conv_block_2(self.num_filter*8,self.num_filter*16,act_fn)
self.trans_1 = conv_trans_block(self.num_filter*16,self.num_filter*8,act_fn)
self.up_1 = conv_block_2(self.num_filter*16,self.num_filter*8,act_fn)
self.trans_2 = conv_trans_block(self.num_filter*8,self.num_filter*4,act_fn)
self.up_2 = conv_block_2(self.num_filter*8,self.num_filter*4,act_fn)
self.trans_3 = conv_trans_block(self.num_filter*4,self.num_filter*2,act_fn)
self.up_3 = conv_block_2(self.num_filter*4,self.num_filter*2,act_fn)
self.trans_4 = conv_trans_block(self.num_filter*2,self.num_filter*1,act_fn)
self.up_4 = conv_block_2(self.num_filter*2,self.num_filter*1,act_fn)
self.out = nn.Sequential(
nn.Conv2d(self.num_filter,self.out_dim,3,1,1),
nn.Tanh(),
)
def forward(self,input):
down_1 = self.down_1(input)
pool_1 = self.pool_1(down_1)
down_2 = self.down_2(pool_1)
pool_2 = self.pool_2(down_2)
down_3 = self.down_3(pool_2)
pool_3 = self.pool_3(down_3)
down_4 = self.down_4(pool_3)
pool_4 = self.pool_4(down_4)
bridge = self.bridge(pool_4)
trans_1 = self.trans_1(bridge)
concat_1 = torch.cat([trans_1,down_4],dim=1)
up_1 = self.up_1(concat_1)
trans_2 = self.trans_2(up_1)
concat_2 = torch.cat([trans_2,down_3],dim=1)
up_2 = self.up_2(concat_2)
trans_3 = self.trans_3(up_2)
concat_3 = torch.cat([trans_3,down_2],dim=1)
up_3 = self.up_3(concat_3)
trans_4 = self.trans_4(up_3)
concat_4 = torch.cat([trans_4,down_1],dim=1)
up_4 = self.up_4(concat_4)
out = self.out(up_4)
return out
なぜかこのモデルだと最後の活性化関数がハイパボリックタンジェントなんだよね。
まとめ
今回は物体検知に有効なU-Netについて簡単にまとめた。
元々は医療用の画像検知に発達したもので、まさかこれが航空写真にまで応用されるなんて開発した人は考えていなかったと思う。
少しはこれで詳しくなれたと思うのでKaggleを頑張る。
参考
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- U-Net: Convolutional Networks for Biomedical Image Segmentation 論文