以前U-NETについての記事を書いたので、今回はその派生元となったSegNetについてまとめてみる。
割とよくまとまっているサイトはあるが自分なりにもわかったこととかまとめていきたい。
SegNetとは
そもそもSegNetとは、画像を意味のある集合に分割していくセグメンテーションをするために考案されたモデル。
イギリスのケーンブリッジ大学にあるComputer Vision and Robotics Groupという団体(?)のメンバーによって開発されたもの。
エンコーダーとデコーダー両方の仕組みをもつ、ピクセル単位で複数のクラスへと画像を分割していくもの。この辺りは構造の解説のところで扱う予定。
以下のサイトのデモがわかりやすいと思う。
SegNet – UNIVERSITY OF CAMBRIDGE
動画だとこんな感じ。
道路上の表示も割と高い精度で読み取れてるし、モデル自体がそこまで重くないため、計算にかかる時間と消費するメモリも抑えられている。これなら自動運転にもある程度応用できそうな感じ。
基本構造
構造は以下の図の通り。
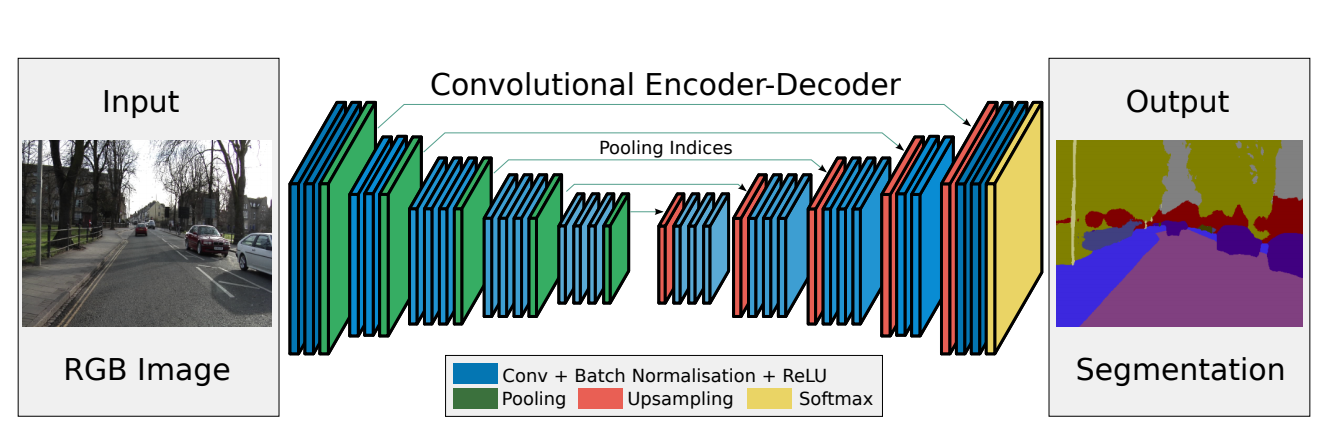
論文より
左右対称(?)になっており、エンコーダーの部分はVGG16と呼ばれるCNNの代表的構造の畳み込み層13層部分が該当している。
この部分に関してはかなりわかりやすいと思うが、問題はデコーダーの部分。
論文の要旨を読んだ感じここでの小さくなった画像のサイズを大きくしてくアップサンプリングの作業が特徴っぽい。
この辺りはFCN(全部が畳み込み層のモデル)とかDeepLab-LargeFOV(これもセグメンテーション用のモデル。アップサンプリングがない)やDeconvNet(今回のSegNetのものより、より深い構造)の構造とかを参考にして作られている。
エンコーダ部分について
エンコーダ部分は先ほど説明したように、この部分は一般的なCNN(畳み込み層を含むニューラルネット)となっており、VGG16のうちのCNN部分に当たる13層がそのまま実装されている。
局所的には
畳み込み層(2~3層)→正規化層→活性化層(ReLU)→プーリング層(ダウンサンプリング)→正規化層
となっている。これを4回繰り返せばエンコーダ部分の完成。
デコーダ部分について
エンコーダ部分でダウンサンプリングされているため、1つ1つの画素値が低い状態となっている。これを元の画像サイズに戻していくのがデコーダ部分。
エンコーダ部分のプーリング層がアップサンプリング層に置き換えれば良い。
アップサンプリング層とプーリング層
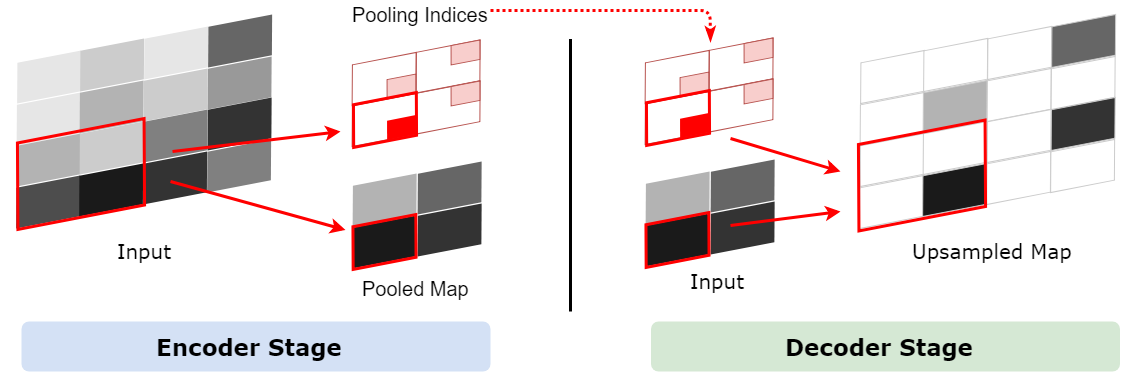
SegNet: 画像セグメンテーションニューラルネットワーク – Qiita より
MAXプーリング層は2×2の画素の範囲から最も大きい値の画素値を取ってくるというもの。
この時、どの画素の値を取ってきたかを記録しておく。
アップサンプリングの際、この記録した画素の位置に値を当てはめる。
その他の場所は空白となる。
これをすることで境界線の判定がより正確にできる。
学習
オプティマイザーはSGDで学習率は0.1で一定。momentumは0.9。
使った学習データはCamVidから得られた道路の映像で、
367の訓練データと233のテスト用のデータを360×480の画像サイズで用いた。
全てRGB値を持っている画像。
これらの画像を道路、建物、車、歩行者、標識、ポール、歩道などといった11個のクラスに分類する。
1バッチは12個の画像データからなり、毎回画像はシャッフルされるが1エポックの中で1回ずつしか各画像は使われない。
損失関数はクロスエントロピー。
バッチ内の損失関数による損失を全て足し合わせたものを使ってパラメータの更新を行った。
クラスによって画像の中に占める画素数が異なるので教師データを元に損失の値に重みをつける必要がある。
この論文ではそのクラスが出てくる頻度の中央値を元に重み付けをしている。
頻繁に出てくるクラスほど重みが小さくなっていく仕組み。
まとめ
論文とそれをよくまとめたサイトの和訳を見ながら今回はSegNetについてまとめて見た。
あまりにも知識不足でCRFとかが何なのかよくわからなかったのでその辺りについても今後まとめていけたら良さそう。
SegNet自身に関しては画像の分割とクラス分けに特化しているもので、自動運転への応用が期待されているモデル。
計算量やメモリ消費量も抑えることで実用性を高めたモデルとなっている。
参考
- SegNet: 画像セグメンテーションニューラルネットワーク – Qiita
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- SegNet – UNIVERSITY OF CAMBRIDGE