[mathjax]
前回の記事で、Echo State Network にリアルタイムで音声を入力して遊ぶということをやった。
詳細は上記記事を参照してほしいが、現状までうまくいっているとは言い難い。この状況を打破するために、少しインプットを行おうということで昨年の 12 月に出ている論文である A Review of Designs and Applications of Echo State Networks を読もうと思う。
37 ページぐらいあるので、全部読むというよりかは気になるところを主に抜粋する。
出てくる画像は特に注釈がない限り、上記論文からの引用。
1. Abstract
- Recurrent Neural Networks (RNNs) は系列データを扱うタスクで有用なことが示されている。
- Echo State Network (ESN) は RNN のよりシンプルなタイプのもので、勾配降下法を使う RNN の代替案として提案された。
- 実用的
- コンセプトがシンプル
- 実装が容易
- 勾配降下法で問題になっている学習の非収束や膨大な計算量を解決できる
- 一方で、運用するには知見や経験を重ねることが不可欠
- 他の機械学習の技術と組み合わせたアプローチが ESN 単体よりも性能が良い
- この論文では、 “basic ESN” と “DeepESN” そして他の機械学習の技術を組み合わせた “combination” の 3 種類に分けて理論的背景やネットワーク設計そして具体的な応用先について論ずる
1. Introduction
1.1 RNN ベースモデルの学習における課題
- 誤差逆伝播で学習を行うが、 分岐(bifurcation) と呼ばれるダイナミクスが劇的に変化する現象が生じることで収束がしずらく計算コストが高い、そして性能の良くない局所最適解に陥ってしまう
- 勾配爆発といった現象も生じうるため、安定した推測パフォーマンスを確保することが困難である
- LSTM や GRU といった改善モデルも出されたが、入力長が限度を超えると勾配が消失してしまう
- LSTM のモデルサイズを大きくすることもできるが、計算が非常に重く時間がかかるものとなってしまう
1.2 Reservir Computing (RC) の登場
- 勾配降下法の代替となる学習法として提案が行われた
- ESN は RC の 1 つの鍵
- さまざまなバリエーションのある状態への高次元写像を行い、強力な非線形マッピングの力を使って入力のダイナミクスの情報処理を行う。
- echo state property は初期状態の影響が無限の遷移のあとには消え去る性質のことを指す
- 似たような短期の変遷を持つ入力があると、似たような内部状態(echo state)が観測される
1.3 Deep Echo State Network (DeepESN) の登場
- RNN 部分の層を重ねることにより、複数のタイムスケールのダイナミクスを扱えるように
- 興味深いポイントは 2 つ
- 層を重ねた RNN が持つ state のダイナミクスに注目が集まった
- ディープなネットワークを時系列データに対して非常に効率的に学習ができる
- ディープラーニングのモデルの種類もたくさん増えてきたよね
2. Basic echo state Networks
2.1 前提知識
Echo State Networks (ESNs)
定義
以下の性質をもつものを指す
- 高速で効率的な RNN
- 入力層、再帰層(リザバー)、出力層から成り立つ
- 入力層と再帰層の重みは初期化以外は固定で、出力層の重みのみ学習が可能(線形回帰)
- 再帰層は多くのニューロンがスパースに結合している
時刻 t での内部状態 \bold{x}(t) \in \mathbb{R}^{N\times 1} は入力 \bold{u}(t)\in \mathbb{R}^{D\times 1} を受けて、以下のように更新される。
\bold{x}(t) = f( \bold{W}_{in} \bold{u}(t) + \bold{W}_{res} \bold{x}(t-1)))
\bold{y}(t) = \bold{W}_{out} \bold{x}(t)
- $f$: 活性化関数。 $tanh$ とか。
- $y(t) \in \mathbb{R}^{M\times 1}$: 出力
- $W_{in} \in \mathbb{R}^{N\times D}$: 入力層と再帰層との結合重み(重みは固定)
- $W_{res} \in \mathbb{R}^{N\times N}$: 再帰層内の結合重み(重みは固定)
- $W_{out} \in \mathbb{R}^{M\times N}$: 出力層(リードアウト)の重み(重みは学習対象)
W_{out} は閉じた形で学習させることができる。||W_{out}X – Y||^2_2 を W_{out} について最小化すれば良いので、
\bold{W}_{out} = \bold{Y} \cdot \bold{X}^{-1}
で求めることができる。(\bold{X} と \bold{Y} はそれぞれ複数の内部状態とそれに対応する欲しい出力をまとめたもの)
ハイパーパラメータは以下の 3 つ。
- $w^{in}$: 入力をスケールするパラメータで、 $W_{in}$ は $[-w^{in}, w^{in}]$ の一様分布で初期化される
- $\alpha$: $W_{res}$ のスパース性を定義する。行列の中で非ゼロの値がどれくらいの割合で入っているのかを決める
- $\rho(W_{res})$ : $W_{res}$ のスペクトル半径。固有値の絶対値の中でもっとも大きい値のことを指す
\rho(W_{res}) を使って、一様分布で初期化された重み行列 W は以下のようにスケーリングが施される。
\bold{W}_{res} = \rho(\bold{W}_{res}) \frac{\bold{W}}{\lambda_{max}(\bold{W})}
\lambda_{max}(\bold{W}) は \bold{W} の固有値の中で最大の値を示す。
リザバーのサイズは N で決められ、入力データは長さ T で D 次元持つものなので、ESN の複雑性は以下のように計算ができる。
C_{typical} = \mathcal{O}(\alpha TN^2 + TND)
Echo State Property (ESP)
ESN の中で特に重要な性質が Echo State Property (ESP) となる。ESP はリザバーが漸近的に入力のみに依存することを数値的に表したものとなっている。定義としては、以下のようになる。
定義
遷移等式 F を持つネットワークが、各の入力系列 U=[u(1), u(2), \cdots, u(N)] と入力状態のペア \bold{x}, \bold{x}’ があったとき、 F が echo state property を持っている時、以下の式が成り立つ。
||F(U, x) – F(U, x’)|| \to 0
(N\to \infin)
ブログ著者コメント:入力が十分に長ければ、内部の状態は初期値にかかわらず入力に依存するということ。
ESP の存在は、 \rho(W_{res}) と 特異値の最大値である \bar{\sigma}(W_{res})=||W||_2 を使って以下のように表現ができる。
echo\ state \ property\ \Rightarrow \rho(\bold{W}_{res})<1
\bar{\sigma}(\bold{W}_{res})<1 \Rightarrow echo \ state\ property
上記の条件は ESN 文脈でリザバーの初期化によく使われている。
一方で、 ESN の初期条件については研究が進んでいる。
例えば、L2 ノルムである ||W_{res}||_2 を拡張した D ノルム ||W_{res}||_D=\bar{\sigma}(DW_{res}D^{-1}) を用いて、十分条件を以下のように拡張した、
\bar{\sigma}(\bold{D}\bold{W}_{res}\bold{D}^{-1})<1 \Rightarrow echo\ state\ property
次に、 Memory capacity (MC) はネットワークの短期記憶(Short-Term Memory) を数値化したものである。MC は W^k_{out} の決定係数 d[W^k_{out}](u(n-k), y_k(n)) = \frac{cov^2(u(n-k),y_k(n))}{\sigma^2(u(n))\sigma^2(y_k(n))} から算出される。このとき、出力層は k ステップ前の入力 u(n-k) を出力するよう学習している。
これを踏まえた Memory Capacity は、以下のように記述できる。
MC = \sum_{k=1}^{\infin}MC_k
MC_k = \max_{\bold{W}^k_{out}}d[\bold{W}^k_{out}](u(n-k), y_k(n))
ブログ著者コメント:Memory Capacity は以下のレポジトリで書籍を参考にしながら実装したことがある。
reservoir_demo/memory_capacity.py at main · wildgeece96/reservoir_demo
2.2 設計
2.2.1 Basic Models
Echo State Networks (ESNs) を初めて提唱したのは 2002 年の Jeager の論文.
2007 年には Jeager らは論文で Leaky-ESN を提案した。
Leaky-ESN は以下の発展式で表記される。
\bold{x}(t) = (1 – \alpha\gamma)\bold{x}(t-1) + \gamma f(\bold{W}_{in}\bold{u}(t) + \bold{W}_{res}\bold{x}(t-1))
- $\alpha \in [0, 1]$: リザバーのニューロンでのリーク率. 値が高いほど直前の state の影響が小さくなる
- $\gamma$: 外部入力と他のニューロンからの値の更新を行う強さ(ゲイン)
Leaky-ESN は時定数を組み込むことでローパスフィルタとなりダイナミクスがゆったりとするようになった。
また、出力をフィードバックとして戻す構造も提案されている。
\bold{x}(t) = (1 – \alpha\gamma)\bold{x}(t-1) + \gamma f(\bold{W}_{in}\bold{u}(t) + \bold{W}_{res}\bold{x}(t-1) + \bold{W}^{back}_{out}\bold{y}(t-1))
これらの原型から、さまざまな形式が提案されている。
2.2.2 リザバーの設計
動的に変化するリザバーの重み
ESN は基本的にリザバー部分の重みは初期化のあとは固定される。しかしながら、重みを固定したリザバーは必ずしも良いパフォーマンスを出すとは限らない。そのため、データ処理の時に動的に変化するリザバーもリザバーを設計するときの 1 つの主な焦点となる。
Mayer らが発表した論文だと、出力を推定するように調整された重み W^1_{out}:W^1_{out}x_t=y(t) と 自己の状態を推定するように調整された出力重み W^2_{out}: W^2_{out}x_t=x_{t+1} を使って、後者の重みを使って内部の重み W_{res} を \hat{\bold{W}}_{res} を更新する
\hat{\bold{W}}_{res} = (1 – \alpha)\bold{W}_{res} + \alpha \bold{W}^2_{out}
\alpha は固定の値。
自己推定の値を入れることで、ノイズへの敏感さをある程度抑えることが可能となる。
Hajnal らが発表した論文では Critical Echo State Networks (CESN) が提案された。ここでは、W_{in} と W_{out} を使うことで非周期的なダイナミクスの近似を行うことができている。
\hat{\bold{W}}_{res} = \bold{W}_{res} + \bold{W}_{in} \bold{W}_{out}
Fan らが発表した論文では、principle neuron reinforcement (PNR) アルゴリズムを提案している。このアルゴリズムを用いて、強化学習的に内部結合の重みを調整するというもの。事前学習段階の出力の重みの値をもとに内部結合の重みを更新する。
\bold{W}_{res}(t) = (1 + \rho(\bold{W}_{res})) \bold{W}_{res}(t-1), if\ \bold{W}_{out} > \xi
Babinec らが発表した論文では、Anti-Oja (AO) 学習を使って W_{res} を更新している。\eta は小さな正の定数。
\bold{W}_{res}(n+1) = \bold{W}_{res}(n) – \Delta \bold{W}_{res}(n)
\Delta \bold{W}_{res}(n) = \eta \bold{y}(\bold{x}(n) – \bold{y}(n)\bold{W}_{res}(n))
この更新によって、隠れ層のニューロン間の多様性が増加し、内部の状態ダイナミクスがよりリッチなものとなる。
Boedecker らが発表した論文では、内在的な可塑性(intrinsic plasticity; IP) をもとに教師なし学習をオンラインで行った。ネットワークの出力は以下のようになる。
\bold{y}(t) = f(diag(\bold{a})\bold{W}_{res} \bold{x}(t-1) + diag(\bold{a})\bold{W}_{in}\bold{u}(t) + c)
- $a$: ゲインベクトル
- $c$: バイアスベクトル
また、a と c の学習は、 Kullback-Leibler ダイバージェンスをもとに学習が行われる。
D_{KL} = \sum p(y)log\frac{p(y)}{\bar{p}(y)}
- $p(y)$: リザバーのニューロンの出力値の分布
- $\bar{p}(y)$: 目指す出力分布 $\bar{p}(y) = \frac{1}{2\sigma}e^{(-\frac{|x-\mu}{\sigma})}$
各ニューロンの出力値がラプラス分布に沿うように \bold{a} と \bold{c} の学習を行う。
これら以外にもいくつか重みの設計方法は存在する。
リザバー内部での複数の結合様式
主なものとして 3 種類存在し、こちらの論文でそれぞれのネットワーク構造の複雑さ(complexity)と記憶容量(MC)の比較を行っている。
- delay line reservoir (DLR)
- フィードバックつき delay line reservoir (DLPB)
- simple cycle reservoir (SCR)
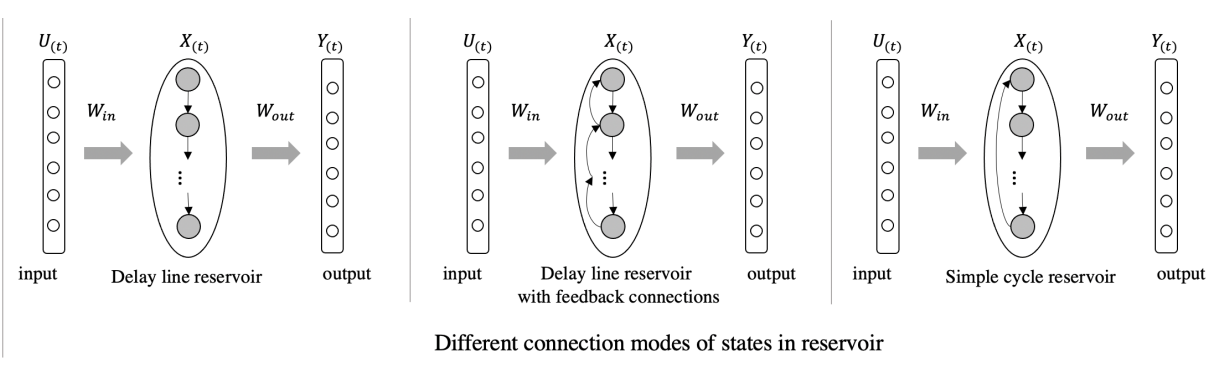
比較の結果 SCR は、標準的な ESN の手法と同等であるという結論になっている。
そのほかにもいくつか提案されている。
ALR(adjacent-feedback loop reservoir) Xiao-chuan らの論文 で提案されている。ALR は SCR をもととしており、他のニューロンの値を次のステップにフィードバックとしてとるようにした構造を持っている。これにより、ネットワークの複雑性(complexity)を下げることに成功したとうたっている。
複数のリザバーのサイズやトポロジーを自動的に設計する目的で Growing ESN (GESN) が提案されている。こちらは、複数のサブリザバーを内包しており、各リザバーごとに隠れユニット数を増加させることでネットワークサイズの増加を行っている。
複数リザバーの様式
1 つのリザバーだけに限らず、複数のリザバーを組み合わせて精度の工場を図ることができる。
Chen らの論文では、 shared reservoir modular ESN (SRMESN) を提案されている。 ESN が内部の中に複数のリザバーを保有するような形で情報処理をしていることになる。
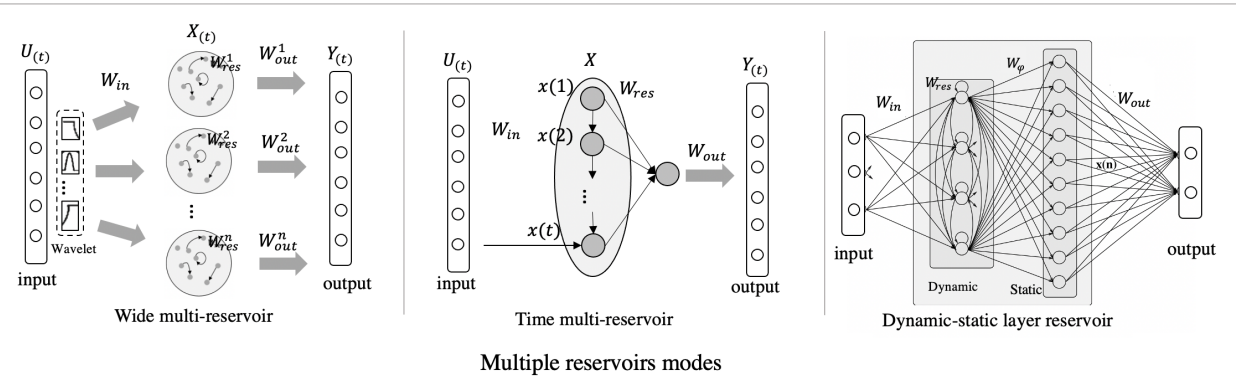
もしくは、出力の \bold{y}(t) が時刻 1 から t までの複数状態(state)を使って計算される、というケースもある(論文リンク)。
残念ながら、複数の時刻を考慮できても線形結合のみのリードアウトだと限界があった。そのため、非線形の出力層を付け加えることを提案した論文も存在した。
また、リザバーの状態 \bold{x}(t) をより高次元な \bold{\Phi}(t) にマッピングをしてから出力する手法も提案されている。これにより、記憶容量と非線形のマッピング性能が上がることが確かめられている。
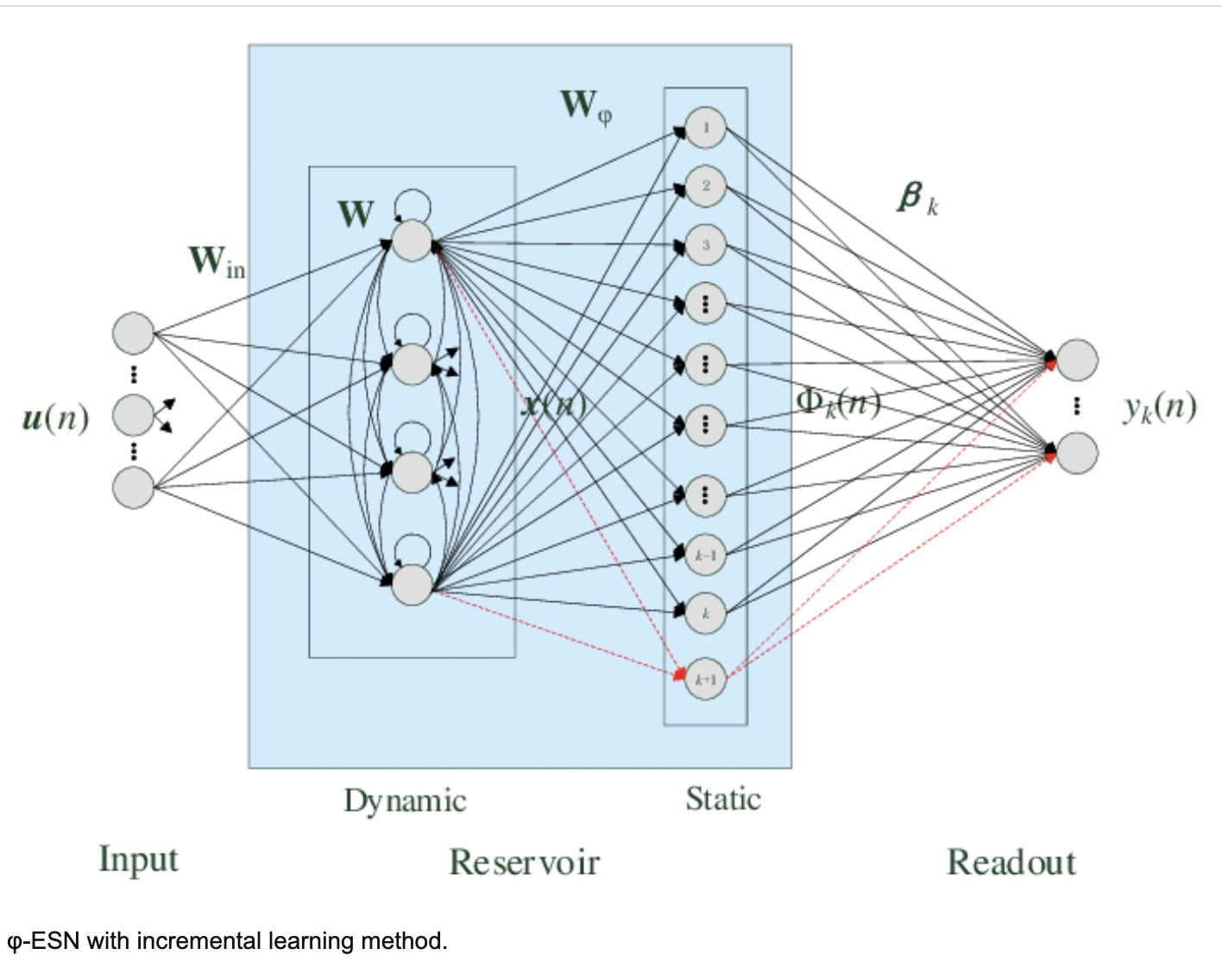
Zhang らの論文 より引用
リザバーの短期記憶についての解析
リザバーの短期記憶を解析する手法はいくつか提案されている。
有名なものは、記憶容量(MC; memory capacity) で、さまざまな入力データをいくつかのステップをずらして再現できるかどうかを確かめていく。
ハイパーパラメータとして、 入力の重み分布の幅を決める w^{in} と スペクトル半径 \rho(\bold{W}_{res}) 、リーク率 \alpha が短期記憶に影響を与うることがわかった。MC の値を最大化する w^{in} の値はリザバーのサイズ N によって変化することと結論づけられている(論文)。
2.2.3 ハイパーパラメータの最適化
スペクトル半径 \rho(\bold{W}_{res}) は 0.8 がもっとも適切だった。settling time (ST) はリザバーの中で入力が処理されてから出力されるまでのイテレーションの回数を示すが、これが長いほど ESN のパフォーマンスに悪影響を与えることが判明している。
最適化のアルゴリズムとして、遺伝的アルゴリズム(GA)やベイズ最適化などが使われている。
また、進化計算(double evolutionary computation)もハイパーパラメータ最適化のために検討されている。
2.2.4 正規化と学習時の設計
- 変分ベイズのフレームワークを使った ESN の学習 (論文)
- リードアウトの重みを入力はターゲットとなる関数の性質とシステム構造の関数として算出する方法(論文)
- データを 1 箇所に集められないケースを想定した分散学習(論文)
- リードアウトの訓練にリッジ回帰を使う方法(論文)
- 学習段階での巨大な線形 ESN の理論的なパフォーマンス解析を重みの初期化手法の観点から行った(論文)
画像は上記論文より引用 - 教師なし学習で進化的な学習方針を ESN に適用(論文).
- 進化的な連続パラメータ最適化で二重倒立振り子問題を解いた(論文)
少ない学習データに対しては、以下のような取り組みがなされてきた。
- Laplacian eigenmap を用いてリザバー多様体を推定し出力の重みを計算(論文)
- よりコンパクトな構造を持つネットワークに差し替えを行う(論文)
- Levenberg-marquardt 法を使って学習の収束と安定性を達成(論文)
- 複数の正規化をハイブリッドを行うことで、大量の出力重みがあった場合で適切に正規化を行う. L_{\frac{1}{2}} 正規化(スパース性とバイアスの除去)と L_2 正規化(重みの大きさ増大の抑制) の 2 つを組み合わせたものとなっている。(論文)
ほかにも、過学習に対する対策として提案されてきた手法は以下のものがある。
- leave-one-out 交差検証を使ってネットワークの構造を自動的に決定する。(論文)
- Bayesian Ridge ESN の提案.(論文)
- Backtracking search optimization アルゴリズム(BSA)により ESN の出力重みを決定すると線形回帰により引き起こされる過学習を回避を(論文)
- スパース回帰最小二乗(OSEAN-SRLS)アルゴリズムを使ったオンラインのシークエンス ESN が提案され、 2 つのノルムスパースペナルティが出力重みにたいしてかけられた。これによりネットワークサイズを制御した。(論文)
また、学習段階においていくつか別の提案がなされている。
- k-fold の交差検証が提案された。この方式では、時間複雑性を支配する要素は一定であり、k によってスケールアップすることはない。(論文)
- モデリングしたシステムのダイナミクスを視覚化するために、 ESN の内部レイヤーの出力を低次元空間にマッピングし正規化の制約を加えたとこと、汎化性能が上昇した(論文)
- 線形に入力を変化させるモデルにより、 ESN に適した入力を学習させた(論文)
- ESN の入力となる特徴量を抽出するために、一連の線形パラメータ可変モデルを使用(論文)
- Hodrick-Prescott (HP) フィルターを入力の前処理として使用。HP フィルターにより 1 つの時系列データから複数の要素を抽出ができる(論文)
3 Deep echo state Networks
複数のリザバー層を重ねることで DeepESN を構築する。
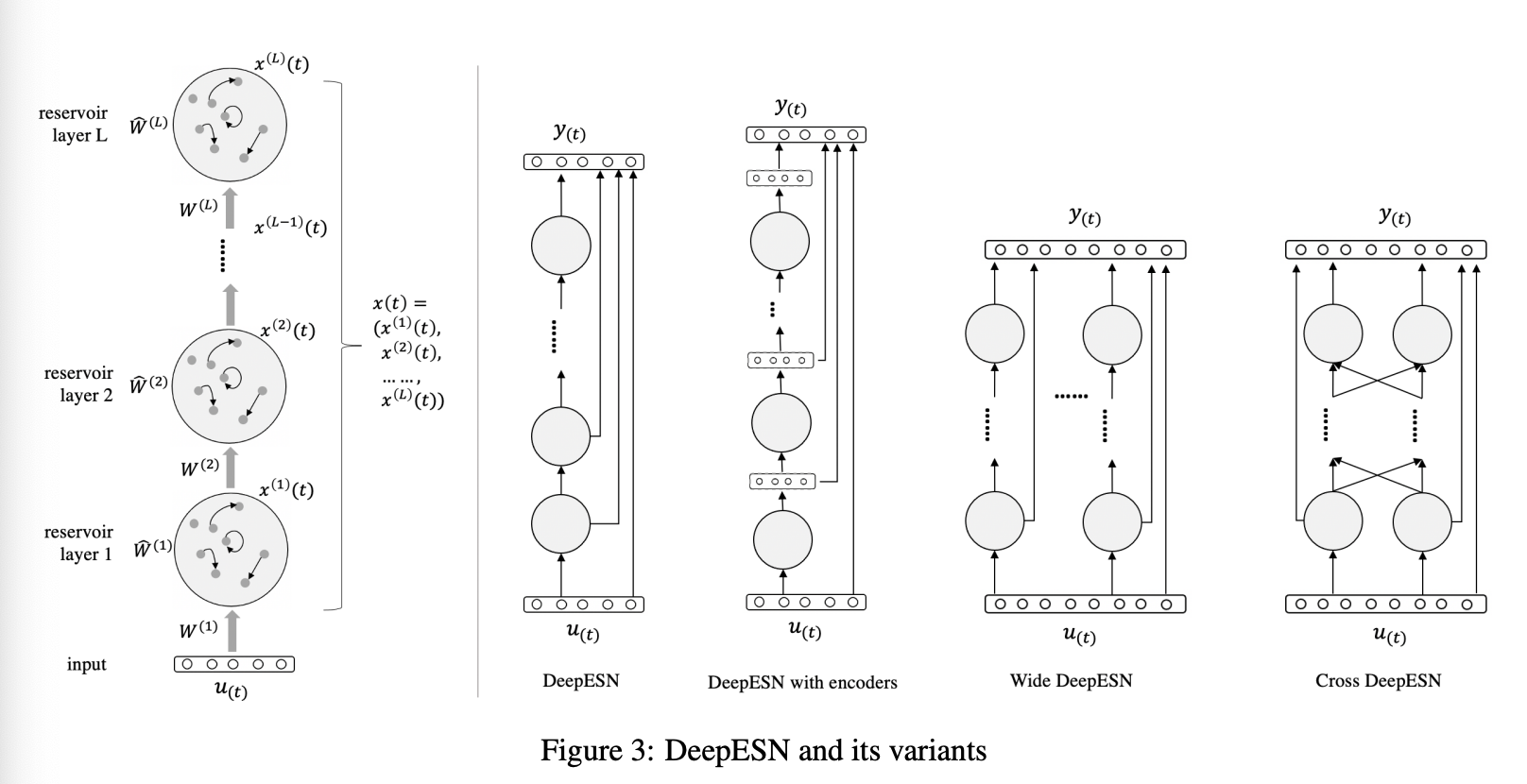
4, 5 は割愛。余裕あったら書き足すかも。
6 Discussion
6.1 Challenges and open questions
ESN は発展してきたけれどもいくつかオープンクエスチョンが残っている。
- リザバーネットワークの変数はどのようにタスクに影響を与えるのか?個別なのかそれとも集合的なのか?そして一般的なのか、個別なのか?
- ネットワーク構造でもっとも良いものって何なのか?各々のタスク構造から最適なネットワーク構造を設計することはできないのか?異なるダイナミクスと異なるベストなリザバー構造とをどのようにして関連づけられるか?
- ESN の制度をどのように担保するか?BP RNN に対して将来取って代わる存在となるのか?
7. Conclusion
この論文では、ESN と 3 つに分類(ベーシックな ESN、DeepESN、他の ML 手法と組み合わせた combination)し、それらに対して理論的な研究、ネットワークデザイン、そして具体的な応用先について述べた。そして、最後にこの領域についてのチャレンジや展望について述べた。
感想
正直、ざっと文字列をおっただけになってしまった。そして、リンクされた論文が基本的に有料でないと見れないものが多く中身が正直ピンときてないものも大半となってしまった。ESN のデザインについては、色々な方法で試行錯誤されているということだとは思うが、やはりまだ DNN のようなブレイクスルーを起こすような発見は出てなさそうである。
また、ネットワークの性能をはかるものも実運用というよりかはまだ理論に近いタスクをベンチマークとしているため、ネットワークの性能がいまひとつピンとこないのもあった。このあたりは、もっと腰を据えて数式を追わないとわからない分野なのだろうなと感じた。