今回は非負値行列因子分解(NMF)についてまとめていく。
非負値行列因子分解は、音声の音源分離や、多次元のデータの次元削減のために使われる手法である。
音声の音源分離について調べてたときにちょうど出てきたのでまとめてみたいと思う。
Pythonでの実装は以下の記事で行った。
– NMFの実装(Python, NumPy)
以下の書籍の内容を自分なりにまとめていく。
Source Separation and Machine Learning 1st Edition
0.概要
NMFは非負の行列  があるとして、非負基底行列(もしくは初めから決めていた行列)の
があるとして、非負基底行列(もしくは初めから決めていた行列)の  と非負の重み行列
と非負の重み行列  の2つの内積に分解する手法である。
の2つの内積に分解する手法である。
(1) ![\[X \approx \hat{X} = BW \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-58059df6248ce0ca8c100b7bbde21583_l3.png "Rendered by QuickLaTeX.com")
これは様々な学習システムに応用されてきた。(文書分類、computer vision、信号処理、レコメンドシステムなど)
分解の対象となる値は 非負である必要がある。非負としたのは、自然界に存在する様々な信号の性質を反映するため。
実際、画像の画素値や音声スペクトログラムの値などは非負となっている。
0.1 音源分離の文脈で
今回は、音源分離の文脈でまとめていきたいと思う。
音源分離だと、 NMFは単音源の音源分離によく使われる。
(複数音源だとICAなどがよく使われる)
 はスペクトログラム値とすると
はスペクトログラム値とすると 個の周波数分の値が
個の周波数分の値が  フレーム分格納されていることになる。
フレーム分格納されていることになる。
https://dsp.stackovernet.com/ja/q/10887 より
横軸が 個分あり、縦軸が個分存在する。
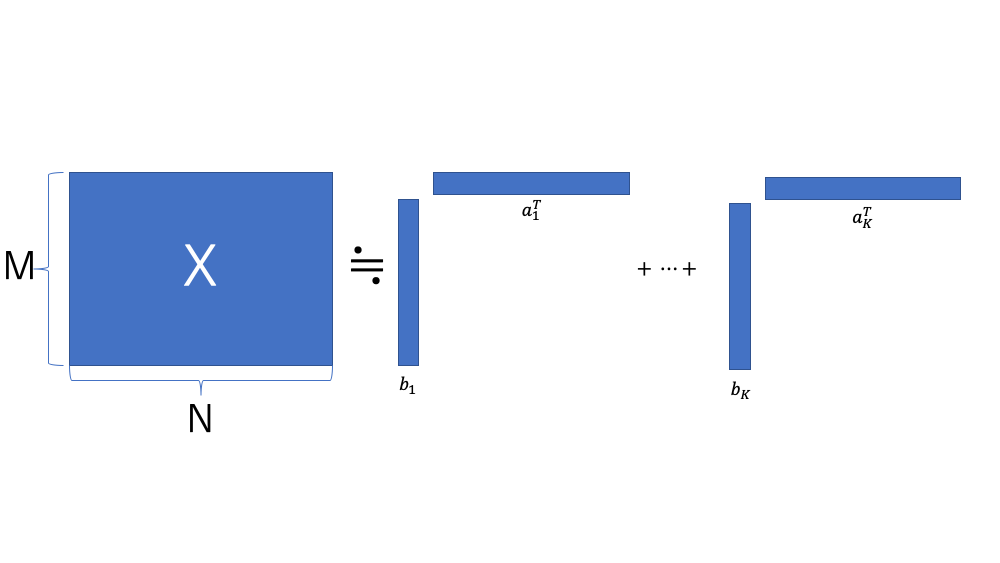
基底行列 は 個の基底ベクトルが並んでいると解釈できる。
個の基底ベクトルが並んでいると解釈できる。
そのため、これらの基底ベクトルに対して重みをつけて足し合わせると、元の信号に再現できることで  を用意する。
を用意する。
を違った見方をすると、の1行1行が分解された信号に対応する重みになる。
(2) ![\[W = A^T = [a_1, \cdots, a_K]^T \in \mathbb{R}^{K\times N} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-cfef858e74a6a745deb8433051cc8418_l3.png "Rendered by QuickLaTeX.com")
このように を1つ1つの行の重みベクトルで構成されていると考えると は以下のように書き換えることができる。
(3) ![\[X \approx BW = BA^T = \sum_k b_k \circ a_k \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-c8de30b312f4f67ae05d738ae68fac16_l3.png "Rendered by QuickLaTeX.com")
( は直積を意味し、前半部分が行、後半部分が列に相当し、それぞれの行、列の位置を変えながら総当たり的に積を求めていく操作である)
は直積を意味し、前半部分が行、後半部分が列に相当し、それぞれの行、列の位置を変えながら総当たり的に積を求めていく操作である)
1.学習過程
1.1 教師あり
欲しい音源  と、その背景音に当たる
と、その背景音に当たる  がそれぞれ強度スペクトログラムで得られるとする。
がそれぞれ強度スペクトログラムで得られるとする。
この時、各々のスペクトログラムの和が実際に得られる信号 で、あらかじめ分離されたものが教師データとして持っている場合を考えてみる。
この時、  、
、 と分解ができ、分解する次元数
と分解ができ、分解する次元数  が、
が、 を満たす時、新たに与えられた信号
を満たす時、新たに与えられた信号  は以下のように表現することができる。
は以下のように表現することができる。
(4) ![\[X_{new} \approx [B^S B^B]W \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-0ed154797224906b221e18d4d0220b58_l3.png "Rendered by QuickLaTeX.com")
ここで、 に含まれる音源と背景音のスペクトログラムの推定値を推定重み行列  で表すと、
で表すと、
(5) ![\[\hat{X}^S = B^S \hat{W}^S \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-baecf62473518c363c0f205d955501c1_l3.png "Rendered by QuickLaTeX.com")
(6) ![\[\hat{X}^B = B^B \hat{W}^B \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-52c08cf99f2f2e32f0690258fbc04498_l3.png "Rendered by QuickLaTeX.com")
これに加えて、Wienerゲインに基づくsoft mask functionにより、分離スペクトログラムの精度がより高まるらしい。
(7) ![\[\tilde{X}^S = X_{new} \odot \frac{\hat{X}^S}{\hat{X}^S + \hat{X}^B} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-703031020fbafa9ac17188360bc352cb_l3.png "Rendered by QuickLaTeX.com")
(8) ![\[\tilde{X}^B = X_{new} \odot \frac{\hat{X}^B}{\hat{X}^S + \hat{X}^B} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-8449ca2091867f8cc85f182129b2b4fe_l3.png "Rendered by QuickLaTeX.com")
ここで、  は要素ごとの積を表している。
は要素ごとの積を表している。
(時間によって変化しない畳み込みフィルタによって得られる周波数領域でのゲインのこと)
Wienerゲインについては、以下のスライドの13ページ目に該当すると思われる。
音声音響信号処理 第10回(WienerフィルタとKalmanフィルタ)
そして、これらによって得られた  をオーバーラップさせながら足し合わせていく逆短時間フーリエ変換を行えば分離された音声を再構成することができる。
をオーバーラップさせながら足し合わせていく逆短時間フーリエ変換を行えば分離された音声を再構成することができる。
1.2 教師なし
今度は分離された教師信号が存在しない場合を考えてみる。
これがかなり現実で多い問題設定になるだろう。
分離したい音源の基底行列  、背景音の基底行列
、背景音の基底行列  とすると、これらを直接得られないため、推定値
とすると、これらを直接得られないため、推定値  を計算する必要がある。
を計算する必要がある。
ここで、元信号 を分解して得られた基底行列  をk-meansなどのクラスタリングアルゴリズムを用いて任意のクラスに分離することができる。
をk-meansなどのクラスタリングアルゴリズムを用いて任意のクラスに分離することができる。
この分離方法にはいくつか存在しており、ベイズ推定によって得る手法も提案されている。(Yang εt al. 2014)
2. 学習手順(Learning Objective)
2.1 概要
 の非負行列が与えられているとする。NMFで、2つの非負行列
の非負行列が与えられているとする。NMFで、2つの非負行列  に分解するのが目的。
に分解するのが目的。
この時、各要素は以下のような対応関係となっている。
(9) ![\[X_{mn} \approx [BW]_{mn} = \sum_k B_{mk}W_{kn} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-be014bba31bf60d566deaae5dd1719c5_l3.png "Rendered by QuickLaTeX.com")
ここで、 の位置 の要素の値はの第
の要素の値はの第 行の次元ベクトルと第
行の次元ベクトルと第 列の次元ベクトルとの内積の値に該当する。
列の次元ベクトルとの内積の値に該当する。
この時、学習対象となるパラメータ集合  は以下の条件を満たすように調整されていく。
は以下の条件を満たすように調整されていく。
(10) ![\[(\hat{B}, \hat{W}) = arg \min_{B,W \geq 0} \mathcal{D}(X || BW) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-de85205edea4fa3a742cbb888b3752ac_l3.png "Rendered by QuickLaTeX.com")
 は2つの値 、
は2つの値 、 との間にある情報量(Divergence)もしくは距離(Distance)を示しており、この値が最小となるような
との間にある情報量(Divergence)もしくは距離(Distance)を示しており、この値が最小となるような  の値を求めていくのが目標となる。
の値を求めていくのが目標となる。
要は、 をよりよく近似できる  の組を何らかの指標を使いながら求めていこうということになる。
の組を何らかの指標を使いながら求めていこうということになる。
得られた勾配などから値を更新していく。
勾配の正のパートと負のパートとに分けて考えると、
(11) ![\[\frac{\partial \mathcal{D}}{\partial \Theta} = [\frac{\partial \mathcal{D}}{\partial \Theta}]^{+} - [\frac{\partial \mathcal{D}}{\partial \Theta}]^{-} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-033b016d7bc987a5d25156bef9463a55_l3.png "Rendered by QuickLaTeX.com")
(12) ![\[([\frac{\partial \mathcal{D}}{\partial \Theta}]^{+} > 0, [\frac{\partial \mathcal{D}}{\partial \Theta}]^{-}) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-8c0acd0098ec5991efd487b8ea03656e_l3.png "Rendered by QuickLaTeX.com")
これらを使ったパラメータ更新式は以下のようになる。
(13) ![\[\Theta = \Theta \odot [\frac{\partial \mathcal{D}}{\partial \Theta}]^{-} \oslash [\frac{\partial \mathcal{D}}{\partial \Theta}]^{+} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-4c36c77d2d46258d451c7377997707dd_l3.png "Rendered by QuickLaTeX.com")
は要素積で、  は要素ごとの商を示す。
は要素ごとの商を示す。
以下では、 の種類によってどのように更新式が変化するかを具体的に見ていく。
2.2 二乗ユークリッド距離(Squared Euclidean Distance)
直接的に距離を求めた指標。
(14) ![\[\mathcal{D_{EU}}(X||BW) = \sum_{m,n} (X_{mn} - [BW]_{mn})^2 \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-dd3f0b1feddb66b632a19514e5e6f444_l3.png "Rendered by QuickLaTeX.com")
それぞれの要素間の距離の二乗を単純に足し合わせたものとなる。
上記の損失関数  を最小化するために以下の更新式にしたがってパラメータを更新していく。
を最小化するために以下の更新式にしたがってパラメータを更新していく。
(15) ![\[B_{mk} = B_{mk} \frac{[XW^T]_{mk}}{[BWW^T]_{mk}} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-c4eec28f2469b8ea85554d2d8c49c4d2_l3.png "Rendered by QuickLaTeX.com")
(16) ![\[W_{kn} = W_{kn} \frac{[B^TX]_{kn}}{[B^TBW]_{kn}} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-f025dd67777c10c881ccfcd40031459a_l3.png "Rendered by QuickLaTeX.com")
更新前の  が非負であれば更新後の値も正になる。
が非負であれば更新後の値も正になる。
和ベースでの更新式に変えると、  の更新式は以下のように書くこともできる。
の更新式は以下のように書くこともできる。
(17) ![\[W_{kn} = W_{kn} + \eta_{kn}([B^TX]_{kn} - [B^TBW]_{kn}) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-1f47b27b07f0e97900fa62ebdc77ccf0_l3.png "Rendered by QuickLaTeX.com")
ここで、 ![\eta_{nk} = \frac{W_{kn}}{[B^TBW]_{kn}}](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-7cf3d7f7407fe8ba70baf47374a4a144_l3.png "Rendered by QuickLaTeX.com") とおくと分数の更新式と同じ形を得ることができる。
とおくと分数の更新式と同じ形を得ることができる。
更新式は以下のように変形することで結果を得ることができる。
![\[\frac{\partial \mathcal D_{EU}}{\partial W_{kn}}\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-5c5fa138d4228f68484002990ff9a44e_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{\partial}{\partial W_{kn}}\sum_{m,n}(X_{mn} - [BW]_{mn})\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-2da8ecff62ae76fd8c07202eae3090b4_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{\partial}{\partial W_{kn}}\sum_{m,n}(X_{mn} - \sum_{k}B_{mk}W_{kn})\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-7201fca25baba58532de25aefd2df61a_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_m(-2 B_{mk}(X_{mn} - B_{mk}W_{kn}))\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-caf58e1645cecc2d5b4eb73ed606b5be_l3.png "Rendered by QuickLaTeX.com")
![\[= -2(\sum_m B_{mk}X_{mn}) + 2(\sum_m B^2_{mk} W_{kn})\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-d65ed3491180f29a8250018f339743f6_l3.png "Rendered by QuickLaTeX.com")
(18) ![\[= -2[B^TX]_{kn} + 2 [B^TBW]_{kn} \ \end{array}\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-74cfe2db79674f750b3a3ebc8e29dc76_l3.png "Rendered by QuickLaTeX.com")
前半部分が ![[\frac{\partial \mathcal{D}}{\partial W_{kn}}]^{-}](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-f52d18d5d1a9a37ba033ec2b25f3470a_l3.png "Rendered by QuickLaTeX.com") ,後半部分が
,後半部分が ![[\frac{\partial \mathcal{D}}{\partial W_{kn}}]^{+}](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-e70ac0d43e3b4a1a777c3a464f113ea7_l3.png "Rendered by QuickLaTeX.com") に相当するので、式(13)に当てはめて計算すれば(16)が導き出される。
に相当するので、式(13)に当てはめて計算すれば(16)が導き出される。
2.3 Kullback-Leibler Divergence
今度は2つの行列の間にある情報量を測る手法について見ていく。
Kullback-Leibler(KL) Divergence は以下のようなエントロピーを求めることで得られる。
![\[\mathcal{D_{KL}}(X || BW)\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-6b27f22ca9d6ae6c9d67074ba8457495_l3.png "Rendered by QuickLaTeX.com")
(19) ![\[= \sum_{m,n}(X_{mn}log\frac{X_{mn}}{[BW]_{mn}} + [BW]_{mn} - X_{mn}) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-025ca0e000e2fb7b062cd7754921b823_l3.png "Rendered by QuickLaTeX.com")
KL Divergenceを最小化していくためのパラメータの更新式は以下のようになる。
(20) ![\[B_{mk} = B_{mk}\frac{\sum_n W_{kn}(X_{mn}/[BW]_{mn})}{\sum_n W_{kn}} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-bfc8ff13061cce4b94175f42a42ca5b6_l3.png "Rendered by QuickLaTeX.com")
(21) ![\[W_{kn} = W_{kn} \frac{\sum_m B_{mk}(X_{mn}/[BW]_{mn})}{\sum_m B_{mk}} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-d579792b913a3ab924bd5f1508a43133_l3.png "Rendered by QuickLaTeX.com")
また、  とすれば、
とすれば、
(22) ![\[W_{kn} = W_{kn} + \eta_{kn}(\sum_m B_{mk}\frac{X_{mn}}{[BW]_{mn}} - \sum_mB_{mk}) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-8a6eee7e7dfed2482213bc7af3ca5400_l3.png "Rendered by QuickLaTeX.com")
2.4 板倉・斎藤 Divergence
板倉・斎藤(IS) Divergence はNMFで使われる損失としてよく使われるものの1つである。
![\[D_{IS}(X||BW)\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-ae6050fd4e73f698f589aa2aa8e3ece2_l3.png "Rendered by QuickLaTeX.com")
(23) ![\[= \sum_{m,n}(\frac{X_{mn}}{[BW]_{mn}} - log\frac{X_{mn}}{[BW]_{mn}}-1) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-7a503119515d467a06614698d2148537_l3.png "Rendered by QuickLaTeX.com")
の更新式は以下のようになる。
(24) ![\[B_{mk} = B_{mk} \frac{\sum_n W_{kn}(X_{mn}/[BW]_{mn}^2)}{\sum_nW_{kn}(1/[BW]_{mn})} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-361363efa4559b46a8b908471b6427bc_l3.png "Rendered by QuickLaTeX.com")
(25) ![\[W_{kn} = W_{kn}\frac{\sum_mB_{mk}(X_{mn}/[BW]^2_{mn})}{\sum_m B_{mk}(1/[BW]_{mn})} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-a602d0f671a55e28ca221b1626ba03dc_l3.png "Rendered by QuickLaTeX.com")
2.5  Divergence
Divergence
より一般的に Divergenceが使われることがある。
![\[\mathcal{D_{\beta}} =\]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-f008d0f09d9dd53bfa3244b0dc1b4cb3_l3.png "Rendered by QuickLaTeX.com")
(26) ![\[\sum_{m,n} \frac{1}{\beta(\beta-1)}(X_{mn}^{\beta}+(\beta -1)[BW]_{mn}^{\beta} - \beta X_{mn}[BW]_{mn}^{\beta-1}) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-41d6e5b5429c4a950b3acc4a0d8ee6e5_l3.png "Rendered by QuickLaTeX.com")
二乗ユークリッド距離( )、KL Divergence(
)、KL Divergence( ), IS Divergence(
), IS Divergence( ) にそれぞれ の値が相当する。
) にそれぞれ の値が相当する。
更新式は以下のようになる。
(27) ![\[B = B \odot \frac{((BW)^{[\beta-2]}\odot X)W^T}{(BW)^{[\beta-1]}W^T} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-2250f295cb49fd806ce17f88752f0f71_l3.png "Rendered by QuickLaTeX.com")
(28) ![\[W = W \odot \frac{B^T(BW)^{[\beta-2]}\odot X}{B^T(BW)^{[\beta-1]}} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-7c3739d68444bc37537420d8d243beeb_l3.png "Rendered by QuickLaTeX.com")
3. スパース性の確保
基底表現にスパース性を確保することで、実際のノイズ混じりの信号からシンプルな基底だけを確保できるようになる。
スパース性を確保するために、損失に正則化項が加わる。
(29) ![\[(\hat{B}, \hat{W}) = arg \min_{B,W \geq 0} \mathcal{D}(X||BW) + \lambda \cdot g(W) \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-a5975fd4f8de80d68bdf43cf50038ab8_l3.png "Rendered by QuickLaTeX.com")
 はモデル正則化のための罰則関数。
はモデル正則化のための罰則関数。
L1正則化かL2正則化がよく使われる。
L1正則化  にすると、KL Divergenceの更新式は以下のように変化する。
にすると、KL Divergenceの更新式は以下のように変化する。
(30) ![\[B = B \odot \frac{\frac{X}{BW}W^T + B\odot(\boldsymbol{1}(\boldsymbol{1} W^T\odot B))}{\boldsymbol{1}W^T + B\odot (\boldsymbol{1}\frac{X}{BW}W^T\odot B)} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-c608b7538844575678c7591c673cdd4c_l3.png "Rendered by QuickLaTeX.com")
(31) ![\[W = W \odot \frac{B^T \frac{X}{BW}}{B^T\boldsymbol{1} + \lambda} \]](https://leck-tech.com/wp-content/ql-cache/quicklatex.com-c1387c0affe050c0b9c3be2eba6053a4_l3.png "Rendered by QuickLaTeX.com")
4. まとめ
今回は、NMFについて書籍に書いてある内容を一通りなぞってみた。
NMFは自然界の信号の性質を加味して非負性を意図的に確保しつつさらにスパース性も加えている基底分解の方法の1つだということがわかった。
手順そのものもICAなどよりかはかなり直接的に求められるのでわかりやすいものになっている。
英語ではあるものの、式などが丁寧に乗っているのでとても読みやすいものになっている。
音源分離について色々知っていきたい。