[mathjax]
今回は、様々なディープラーニングを使った物体検出のアルゴリズムが存在する中で、最近のものの元となっているR-CNNについてまとめていく。
概要
R-CNN(Regional CNN)は物体の領域と種類とを同時に検出する目的で開発された。

上の画像のように、画像が何を表しているかだけでなく、どこにあるのか についても同時に検知して(localize)くれる。
原論文[1]より
実績
ILSVRC2012と呼ばれる、120万件あるイメージデータに対して1000クラスラベル付けされたものを学習して、どれだけ精度よくラベル付けを行うことができるかというコンペティションで堂々の1位をとったモデルとなっている。
しかも2位以下よりも10%以上も精度が良かった。
1つのイメージに対してラベルの候補となる上位5つのクラスに正しいラベルが含まれていない確率が15%ほどとなっており、2位以下のチームの誤認識率は26%以上もあった。
ここまで差をつけられるといっそ清々しい。
実用例
致命的な欠点である計算量の膨大さからこのモデルそのものが利用されている例はサイトで検索した感じだとすぐには見つからなかった。
これらの改良版となっているFaster R-CNN(R-CNNを2、3段階改良したもの)などは自動運転技術などに使われているようだ。
動画だとこんな感じ。
仕組み
ここからはR-CNNの構造について見ていく。
まずは候補となる領域の生成(bounding boxes)
- 入力:画像
- 出力:検出した物体を囲った四角と各々に対応するラベル
このような囲った四角を英語ではBounding boxとか言う。

Selective Search for Object Recognition(論文)より
上の画像のように、Selective Search と呼ばれる手法を用いて物体の候補となる領域を作り出している。
手順としては以下の通り。
- 画像の特徴量(色合いや濃淡勾配など)を元に画像をいくつかの領域に分けていく。
- 類似度を元に領域を結合していく。
- 程よい大きさになるまで結合を続けていく
- 分けた領域を元に候補となる領域(四角形)を生成していく
他にも色々手法はあるようだが、R-CNNは特定の領域生成手法による効用が全く分からなかったので、とりあえず他の研究結果と比較できるようSelective Search を選んだということらしい。
ここで生成される領域はfast modeでも2000個ほど。
候補となる領域ごとにCNNをかける
次に候補となる領域を生成したら、そこから畳み込み層をかけ、特徴量を抽出する。
ここの過程は従来のVGG16やAlexNet、GoogLeNetを使う。
ImageNet2012で優勝したAlexNetを使っている。
領域をRGB情報を含む同サイズの正方形の画像にリサイズし、更に画素値の平均を差し引いたものを
- 5層の畳み込み層(CNN)
- 3層の全結合層
に入れ込んだ。
最後の全結合層のところで1000クラスそれぞれの確立を予想している。
以下の画像の通りで、2つの道筋に分かれており、全結合層で合流する形となっている。
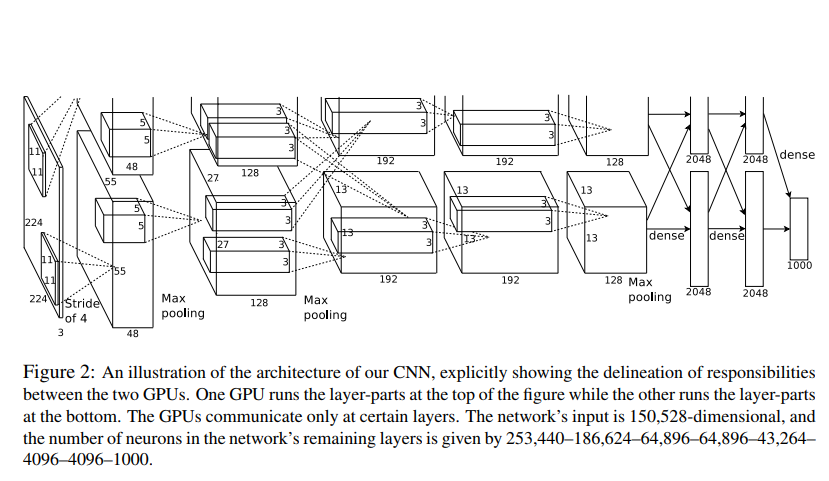
論文[2]より
活性化関数はReLUを使う
活性化関数にはReLU関数を使っている。
tanh(x) や、やシグモイド関数 (1+e^{-1})^{-1}
が一般的だが、学習時間の短さなどの理由からReLU関数を使っているらしい。
畳み込み層出力の正規化
いわゆるバッチノーマライゼーション(Batch Normalization)だが、これを1つ1つの層全体に行うのではなく一部だけを対象 に行っているのが特徴。
論文ではLocal Response Normalizationとか表現している。
例えば、i番目のチャンネルから出力された位置(x,y)での出力された値をa^i_{x,y} (ReLUを適用済み)
とし、nとkを定数、Nを全体のチャンネル数とすると、正規化した結果の値をb^i_{x,y} として、次のように書ける。
b^i_{x,y} = \frac{a^i_{x,y}}{(k + \alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2} (a^j_{x,y})^2)^{\beta}}
論文[1]と[2]の著者たちはk=2,n=5,\alpha=10^{-4},\beta=0.75を使った。
全体のチャンネル数が48,128,192,192,128となっていることからもかなり局所的な正規化を行っていることがわかる。
これをするだけで結果が1.4%ほど向上したとのこと。正規化すごい。
プーリング
次に画像サイズを小さくするプーリングについて。
通常のプーリングではプーリングするサイズと1回あたりのスライドする距離とが同一で、プーリングするエリアが被らないようになっているが、ここでは1回にプーリングする領域を広げることで元の画像からプーリングされる領域に被りが出るようになっている。

the morning paperより
ここでは3×3のプーリングフィルターにピクセル2個分のスライドをさせている。
これにより精度の若干の向上(0.4%ほど)と、わずかながらの過学習のしにくさが観測された。
SVMを使った分類
CNNを使って特徴量を抽出したあとはSVMを使って分類を行う。
SVMはそれぞれの領域から最も距離が遠くなる(マージンが最大になる)ように境界面を設定する手法。
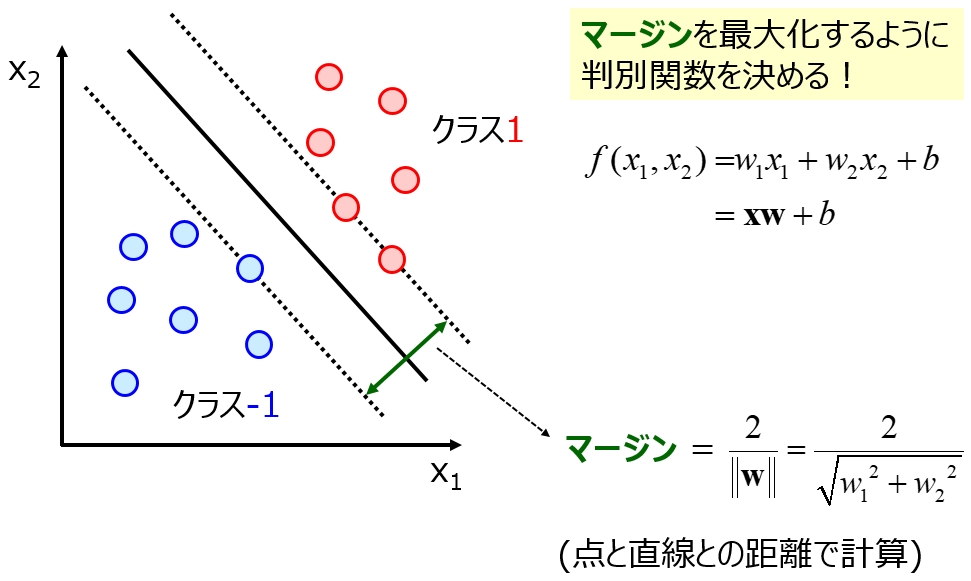
サポートベクターマシン(Support Vector Machine, SVM)~優秀な(非線形)判別関数~より
図であらわされているのは2次元2クラスのものだが、これを多次元他クラスに拡張したものを使った分類を行っている。
分類するクラスの数は識別したい物体の個数に1を加えたもので、加えたものは背景画像のクラスになる。
これで各領域ごとのラベル付けが完成した。残るはこれらのラベルを選定していくことだけ。
同じラベルで被った領域の消し方(non-maximum supression)
領域ごとのラベル付けが完了したお終いというわけにはいかず、このあと同じような領域で同じようなラベルのものが出てきてしまう。
これらをある指標に沿って削っていかなければならない。
前提知識(IoU)
これについて語る前にIoUについて簡単に触れておく必要がありそう。
Intersection over Unionの略となっている。
IoUとは、簡単にいえば領域の重なり具合を数値にあらわしたもので、領域Aと領域BとのIoUは以下のようになる。
IoU = \frac{A\land B}{A \lor B}
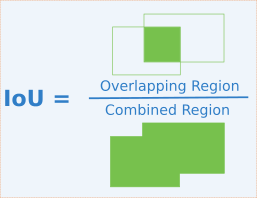
Intersect over Union (IoU) – Ronny Restrepoより
本題
ではIoUを使って領域を削っていく。
同じラベル且つかぶりがある領域同士のIoUのスコアを計算し、あらかじめ指定しておいた閾値(例えば0.3とか)を超える領域同士は片割れを消していく。
こうして消していくと指定した最大値を超えない領域だけが残っている。
これでnon-maximum suppressionの意味が分かると思う。
わかりやすい解説をしてくれたサイトがいかにあるのでこの説明でピンとこなかった人は見てほしい。
物体検出におけるNon-Maximum Suppressionのアルゴリズム | meideru blog
損失関数
これで一通りのモデル解説が終了した。次からは学習を進めるうえで損失関数を設定する。
損失関数は2段階設定する
学習を進める用の損失関数はbounding-boxを回帰させるためのものと、クラス分けする用の損失関数を設定する必要がある。
クラス分けをする部分はCNN自体は学習済みのモデルを使っているので畳み込み層から出力された特徴量からSVMに通す部分のみを学習するfine-tuningを行っている。
領域分けのための損失関数
学習の進め方の原理としては著者の理解が間違ってなければ、Selective Searchを使って提案された領域自体は変化されないので、その提案された領域をどう変化させるかが学習を進めていくポイントとなる。
まずi番目の画像について、{(P^i,G^i)}_{i=1,\cdots,N}の2組のパラメータ群があるとして、P^i = (P^i_x,P^i_y,P^i_w,P^i_h)が予想したバウンディングボックスだとして(x,yはボックスの位置でw,hはボックスの大きさ)、G^i = (G^i_x,G^i_y,G^i_w,G^i_h)が真の値となる。
この2つの設定したパラメータを元に新たなベクトルPに関する関数を4つd_x(P),d_y(P),d_w(P),d_h(P)設定する。
\hat{G}_x = P_wd_x(P) + P_x \
\hat{G}_y = P_hd_y(P) + P_y \
\hat{G}_w = P_wexp(d_w(P)) \
\hat{G}_h = P_hexp(d_h(P)) \
このように設定した4つの関数を使って真のGの値を予測する。
先ほど設定した4つの関数 d_\star(P) は線形関数で関数\phi_5(P) を使って
d_\star(P) = w_\star^T\phi_5(P)
とあらわされる。
(★にはx,y,w,hが入る)
ここでパラメータ w_\star は以下の値を最小化する値を使う。ここではリッジ回帰を使いパラメーターの正則化項を加える。
L = \sum^N_i (t_{\star}^i – \hat{w}_{\star}^T \phi_5(P^i))^2 + \lambda |\hat{w}_{star}|^2 \
ここで設定した損失関数の値を最小化する。
ちなみにここで設定したt_\star(★=x,y,w,h)は
t_x = \frac{(G_x – P_x)}{P_w} \
t_y = \frac{(G_y – P_y)}{P_h} \
t_w = log(\frac{G_w}{P_w}) \
t_h = log(\frac{G_h}{P_h}) \
パラメータの正則化項は重要で、論文内では\lambda=1000の値に設定している。
注意が必要なのは、学習に使う(P,G)の組を選ぶときである。
仮にPとGが離れすぎていると学習させる意味がないからだ。
この離れ具合は先ほど扱ったIoUを使う(論文での閾値は0.6)。
R-CNNの問題点
計算量が致命的に多い
計算量がめちゃくちゃ多いせいでGPUを用いても1つの画像を予測するのに数十秒かかってしまう。
1つの画像に対して2000回もCNNを通しているから当たり前ではあるが、やはり膨大。
今後の課題として計算量を減らせるようなモデルを考案する必要が出てきた。
ただ、認識精度の部分では目を見張るものがあったため、何とかして計算量を減らそうとR-CNNを元にして計算量がより少なく、より早く学習できるようなモデルがどんどん考案されていく。
まとめ
今回まとめたR-CNNはディープラーニングを使った物体認識を、物体のクラス分けに加えて物体の位置を認識する次のステージに進める大本となっているモデルである。
これの改良版を作っていく形でいろいろなモデルができていった。
有名なのはFast R-CNNとFaster R-CNN、更に物体の形を抽出するmasked R-CNNが出てきている。
SSDやYOLOもある。
今後はこのあたりもまとめていく予定。
参考
論文関係
- [1] Rich feature hierarchies for accurate object detection and semantic segmentation
Tech report (v5),Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik
UC Berkeleylink - [2] ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky et al. link
サイトなど
- Large Scale Visual Recognition Challenge 2012
- Deep Learningによる一般物体検出アルゴリズムの紹介
- R-CNNの原理とここ数年の流れ – SlideShare
- A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
- 物体検出におけるNon-Maximum Suppressionのアルゴリズム | meideru blog
- Deepに理解する深層学習による物体検出 by Keras – Qiita